Przeglądarki stron WWW są na tyle ważnymi programami, że w pewnym okresie rozwoju Internetu (głównie druga połowa lat 90.) można było nawet zaobserwować zjawisko określane "wojną przeglądarek" -- przepychanki i walka "na funkcje" pomiędzy Microsoftem i Netscape. Zawierucha wojenna ominęła jednak świat uniksów; po części dlatego, że użytkownicy tych systemów nie mieli wielkiego wyboru (był tekstowy Lynx, graficzna Netscape; wcześniej dominowała Mosaic), po części zaś dlatego, że z uniksów korzystano w zupełnie innym gronie osób niż z MS Windows -- przeważnie byli to akademicy i inżynierowie, którym nie było spieszno do eksploracji coraz to cudaczniejszych witryn WWW, a jedynie zależało na pobraniu konkretnych i rzetelnie przedstawionych informacji.
Teraz sytuacja się zmieniła: Linux jest dla wszystkich, a więc wymagania względem przeglądarek wzrosły. Na szczęście, nie mamy do czynienia z żadną "wojną" -- w ogóle nie jest to chyba możliwe w środowiskach otwartych -- powstało za to mnóstwo przeglądarek WWW i zaistniała zdrowa konkurencja wśród producentów.
W niniejszym artykule postaramy się nieco "rozejrzeć" po przeglądarkach dostępnych dla systemu Linux. "Pod ostrzał" pójdzie 10 programów; nie są to wszystkie przeglądarki działające pod Linuksem, a jedynie te, które autor uważał za najpopularniejsze i najbardziej charakterystyczne. Testowane aplikacje reprezentują bardzo różne "gatunki": są przeglądarki graficzne, są tekstowe, jest nawet przeglądarka wbudowana w pakiet biurowy.
Kiedy zabierałem się do pisania tego artykułu, sądziłem, że kilka tygodni wystarczy na przetestowanie na wskroś 10 programów. Nic bardziej błędnego. Przeglądarki to aplikacje bardzo złożone, a testowanie powinno odbywać się na wielu poziomach i najlepiej przez wiele osób. Im bardziej zagłębiałem się w tworzenie stron testowych i samo testowanie, tym więcej odkrywało się możliwości i kontekstów testowania. Dlatego ten artykuł należy postrzegać jedynie jako wstęp do oceny współczesnych przeglądarek linuksowych. Udało mi się sprawdzić obsługę tylko wybranych elementów i cech HTML-a i CSS oraz ocenić tylko najważniejsze funkcje samych programów. Obsługę Javy sprawdziłem jedynie pobieżnie, a wcale nie zdążyłem zająć się językiem JavaScript, obsługą plików multimedialnych, ciasteczek itp. Dlatego chciałbym w tym miejscu zaprosić Czytelników do wspólnego testowania i uzupełniania wyników. Artykuł jest dostępny i aktualizowany pod adresem http://kolos.math.uni.lodz.pl/~ap/przegladarki/; pod tym adresem będzie można również znaleźć "zestaw testowy", którym (między innymi) badałem przeglądarki -- jeśli Czytelnicy mają pomysły na nowe testy lub udało im się przetestować nowe cechy, również proszę o kontakt.
Przetestowano poniższe przeglądarki, w następujących wersjach (o ile w artykule nie zaznaczono inaczej).
Przeglądarki testowano na komputerze "silnym" (Duron 700 MHz, 128 MB RAM-u, grafika TNT2 32 MB) oraz (niektóre) na "słabym" (laptop Pentium 150 MHz, 48 MB RAM-u, grafika C&T 2 MB). Na obu zainstalowano dystrybucje Mandrake 8.0, jądro 2.4.3, system X Window 4.0.3 z KDE (komputer silny) oraz z menadżerem okien Enlightenment (słaby). Zastosowano wirtualną maszynę Javy firmy Sun (1.3.1); choć teoretycznie inne JVM-y powinny działać równie dobrze, nie udało mi się uruchomić wirtualnej maszyny Blackdown (w Mozilli dowolny aplet powodował zawieszenie przeglądarki, a Konqueror w ogóle nie potrafił apletu załadować).
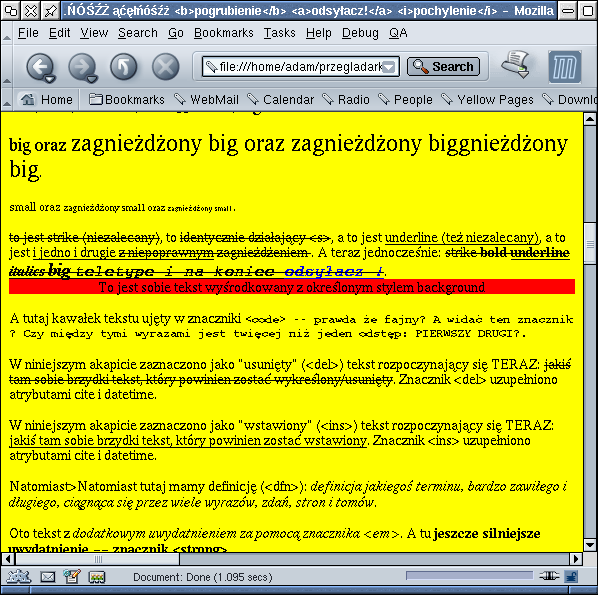
Mozilla doskonale radzi sobie ze znacznikami formatującymi oraz logicznie opisującymi zawartość.
Projekt Mozilla (http://mozilla.org) powstał po upublicznieniu przez firmę Netscape wersji źródłowej przeglądarki Navigator na początku 1998 roku, w samym środku "wojny przeglądarek". Nazwą Mozilla powraca do "antycznego" pierwowzoru Navigatora, jednak w istocie jest to produkt niezwykle nowoczesny i budowany na nowoczesnych zasadach otwartych źródeł (licencja NPL Mozilli jest zbliżona do GPL i BSD). Projekt koordynowany jest na stronie http://mozilla.org; poszczególnymi modułami zajmują się różni programiści, w tym wielu z firmy Netscape -- nic dziwnego, to właśnie na bazie Mozilli oparty jest najnowszy produkt tego producenta, Netscape Navigator 6. W ogóle pomiędzy Mozillą i Netscape istnieje wiele wzajemnych zależności; nie powinno się jednak mieszać tych dwóch nazw, ponieważ opisują one różne organizacje i różne przeglądarki.
Właściwie pojęcie "przeglądarka" jest w tym przypadku dużym uproszczeniem. Mozilla to ogromny projekt, w którym postawiono na modularność. Są moduły właściwej przeglądarki, moduły pocztowo-newsowe, moduły związane z bezpieczeństwem, "front-endy" i wiele, wiele innych. A ponieważ projekt jest otwarty, wszystkie one mogą być wykorzystywane w dowolny sposób i niezależnie w najrozmaitszych zastosowaniach -- zaprezentowano nawet prototypowe przenośne urządzenia dostępowe oparte na wybranych modułach Mozilli! Modułem najbardziej znamienitym dla niniejszego artykułu jest NGLayout ("Next Generation Layout"), zajmujący się interpretacją i wyświetlaniem kodu HTML, a znany pod bardziej popularną nazwą Gecko.
Programiści projektu Mozilla mają do dyspozycji zaawansowane narzędzia. Na przykład, interfejsy użytkownika tworzone są z wykorzystaniem specjalnego języka XUL, dzięki któremu nie trzeba wykonywać tej samej pracy przy tworzeniu interfejsów dla różnych platform; takich narzędzi umożliwiających "uogólnienie" i modularyzację kodu jest więcej. I jeszcze: Mozilla napisana jest głównie w C++, a nie -- jak czasem się słyszy -- w Javie.
Należy pamiętać, że zarówno Mozilla, jak i zbudowana na jej bazie Netscape 6 nijak się mają do poprzednich wersji Navigatora -- serii 4.x i wcześniejszych. Rozwój tamtych przeglądarek został całkowicie zarzucony i programiści Netscape (oraz Mozilli) zaczęli praktycznie wszystko od zera, stawiając sobie za cel stworzenie przeglądarki maksymalnie standardowej i modularnej.
Galeon (http://galeon.sourceforge.net) jest przeglądarką działającą w środowisku GNOME i opartą na mechanizmie przetwarzania Gecko rodem z Mozilli; dlatego aby w ogóle ją uruchomić, w systemie musi być również zainstalowana Mozilla (oczywiście, oprócz standardowych bibliotek GNOME, takich jak GTK+, libgnome, libglade itd.).
W Galeonie postawiono na prostotę. Jak mówią sami programiści -- ich przeglądarka jest przeglądarką, a więc nie czyta poczty, nie zarządza plikami, nie potrafi przesyłać komunikatów, no i nie robi kawy. Jest to bardzo odmienne podejście od tego zastosowanego w Mozilli i Netscape 6 -- tam interfejs użytkownika jest przeładowany różnorakimi funkcjami, co oczywiście prowadzi do spowolnienia pracy.
Nautilus jest tym dla GNOME, czym Konqueror dla KDE -- ten "kombajn" równie dobrze służy do przeglądania stron WWW, co do podglądania zawartości plików i zarządzania nimi. To także -- podobnie jak Konqueror w KDE -- domyślny czytnik plików pomocy. Twórcy określają Nautilusa mianem "powłoki graficznej dla GNOME". Na potrzeby przeglądania stron WWW Nautilus wykorzystuje biblioteki Mozilli. Jeszcze niedawno Nautilus sponsorowany był przez firmę Eazel; obecnie firma ta zaprzestała wspierania projektu, co jednak nie oznacza, że Nautilus przestanie być rozwijany. Nautilus domyślnie uruchamiany jest z własnym pulpitem i ikonami; aby tak się nie działo, wystarczy przy "odpalaniu" zastosować opcję --nodesktop.
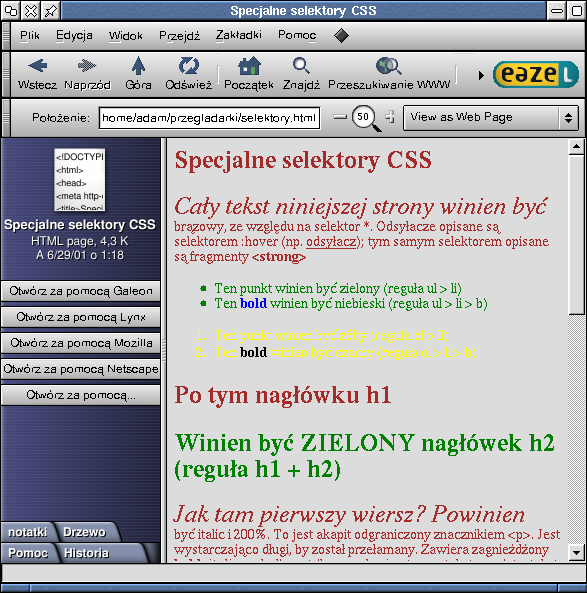
Oparty na Mozilli Nautilus (tutaj jeszcze pod banderą firmy Eazel) nie ma problemów ze specjalnymi selektorami CSS.
Konqueror (http://www.konqueror.org) to flagowy produkt zespołu KDE, następca programu kfm z pierwszej wersji KDE. Stanowi zarówno przeglądarkę, jak i menadżer plików oraz "viewer" dla tego środowiska graficznego. Podstawę przeglądarki stanowi zaawansowany mechanizm interpretacji kodu HTML o nazwie khtml; jest on modułem KPart i jako taki może zostać wykorzystany w innych programach dla KDE.
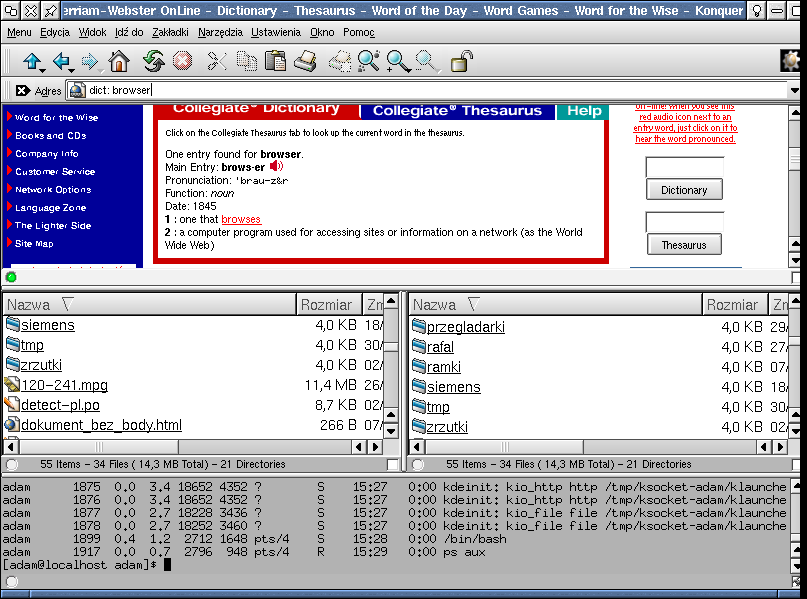
Tak -- to wszystko to tylko jedna aplikacja, Konqueror. Jednocześnie wyświetla stronę, służy jako menadżer plików oraz emuluje terminal.
Przez dość długi czas przeglądarka Netscape 4.x była praktycznie jedynym (po antycznej Mosaic) wyjściem dla osób pragnących oglądać strony WWW pod uniksami w trybie graficznym. Jest to przeglądarka w wersji z czasów najbardziej zażartej "wojny przeglądarek" i obsługuje wiele niestandardowych rozszerzeń HTML-a i innych. Po wielu aktualizacjach jej kod, choć w pewnej chwili udostępniony publicznie, okazał się na tyle zagmatwany, że postanowiono napisać przeglądarkę od nowa. Tak powstała Netscape "o dwa numery większa" (wersja 6), zbudowana na bazie zasobów Mozilli (tak, przeglądarka Netscape 5 pojawiła się również i stanowiła punkt wyjścia dla projektu Mozilla -- istniała jednak bardzo krótko i nie zdobyła popularności).
Przeglądarka norweskiej firmy Opera Software (http://www.opera.com). Została stworzona przez programistów pracujących dla norweskiego operatora telekomunikacyjnego i pojawiła się na pulpitach użytkowników w roku 1996 (wersja 2.1), a więc w początkowym okresie "wojny przeglądarek". Początkowo nie mogła stawić czoła dwóm gigantom technologicznym i marketingowym, jednak ostatnio grono jej użytkowników staje się coraz szersze, a sama Opera jest bardzo aktywnie rozwijana. Dość ciekawym zjawiskiem, którego raczej nie zauważa się w przypadku innych "browserów", jest fakt silnego przywiązania użytkowników do Opery -- powstają nawet fankluby tej aplikacji; potwierdzałoby to zapewnienia producenta, że "kto raz spróbuje Opery, ten nie wróci już do innych przeglądarek". Od wersji 4 z dobrodziejstw Opery mogą już korzystać również użytkownicy Linuksa. Początkowo program był rozprowadzany na zasadach shareware; obecnie jest darmowy, ale użytkownik musi oglądać reklamy pojawiające się w pasku narzędzi (nie wpływa to na prędkość przeglądania, ponieważ "bannery" pobierane są tylko raz na tydzień i przechowywane w lokalnej pamięci podręcznej). Nie są dostępne źródła programu; miejmy nadzieję, że taki stan długo nie potrwa.
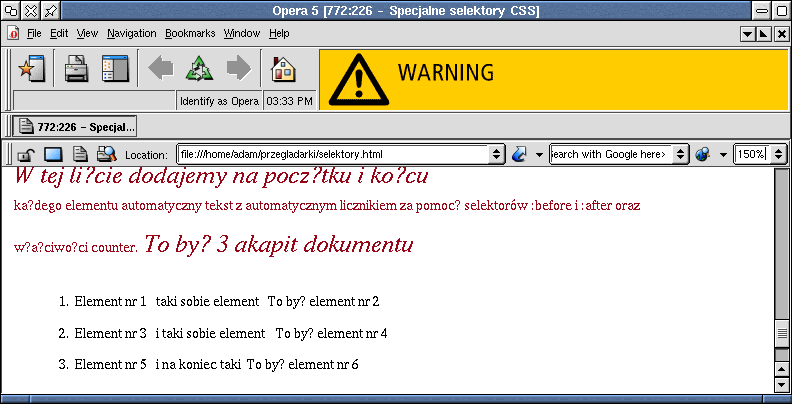
Opera jako jedyna obsługiwała specjalne selektory before: i after:. Gdyby nie te ogonki...
Pakiet biurowy StarOffice został przejęty przez Suna wraz z jego pierwotnym producentem, firmą Star Division. StarOffice to pakiet-gigant, wzorowany na produkcie Microsoftu, obejmujący procesor tekstu, arkusz kalkulacyjny, bazę danych i inne aplikacje. Jedną z funkcji jest możliwość przeglądania (i ewentualnie edycji) stron WWW. Przeglądarka WWW jest w pełni zintegrowana z pozostałymi częściami pakietu. Między innymi oznacza to, że dowolną stronę WWW możemy zapisać np. w formacie StarWritera.
Kiedy trzech programistów uniwersytetu w Kansas projektowało program Lynx, usługa WWW co prawda już istniała, jednak pierwszy Lynx... nie był przeglądarką WWW! Program służył do szperania w lokalnych zasobach akademickich oraz jako przyjazny interfejs "świstaków" (usługi Gopher). Obsługiwał własny format hipertekstowy i działał na terminalach tekstowych, w oparciu o bibliotekę curses. Dopiero potem dołączono procedury obsługi WWW. Coraz popularniejszy HTML wkrótce wyparł własny format hipertekstowy Lynksa. Dziś Lynx jest najpopularniejszą przeglądarką tekstową, a jego zagorzali zwolennicy uwielbiają dokuczać "postępowym" webmasterom, wysyłając im e-maile o treści w rodzaju "wasza strona jest do kitu -- pod moją przeglądarką jej nie widać". To dlatego, że "Ryś" jest tekstowy i konserwatywny -- strony naładowane multimediami i korzystające z całej gamy wtyczek pod Lynksem zupełnie nie zdają egzaminu.
Zacznę od cytatu ze strony programu: "Textovy browser. Neco jako lynx. Umi to tabulky a ma to BFU-friendly interface. Bezi pod Unixem a OS/2."... i chyba wszystko jasne! Links (http://artax.karlin.mff.cuni.cz/~mikulas/links/) autorstwa czeskiego programisty Mikulasa Patocky to -- jak pisze sam autor -- przeglądarka "trochę taka jak Lynx". Ale podobieństwo ogranicza się głównie do nazwy oraz faktu, że Links pracuje w trybie tekstowym. Poza tym jest to zupełnie inny program, który dzięki niektórym bardzo ciekawym cechom zyskuje coraz większą popularność i odbiera "elektorat" Lynksowi.
Emacs/W3 (http://www.cs.indiana.edu/usr/local/www/elisp/w3/docs.html) to "kolejny powód, by w ogóle nie opuszczać programu Emacs". Jest to pełnoprawna przeglądarka WWW, działająca "wewnątrz" edytora Emacs (lub XEmacs). Została napisana w języku Emacs-Lisp i -- jak wiele rozszerzeń Emacsa -- dołączana jest do niego jako opcjonalny pakiet. Strony WWW są wyświetlane jako kolejne bufory, na których można wykonywać różne czynności za pomocą skrótów klawiszowych znanych każdemu wielbicielowi edytora spod znaku łba antylopy. W3 stanowi jeden z dowodów na to, że "za pomocą Emacsa można zrobić wszystko". Jeśli pakiet W3 jest już zainstalowany w systemie, to jego uruchomienie sprowadza się do wydania polecenia w3 podczas sesji (X)Emacsa.
HTML w wersji 4.01 to obecnie obowiązujący język stron WWW. Zadaniem programu o nazwie "przeglądarka WWW" powinna być właściwie tylko obsługa tego jednego standardu oraz specyfikacji towarzyszących (np. CSS). Jak wiadomo, większość przeglądarek potrafi o wiele więcej i takie są również oczekiwania użytkowników i autorów stron -- zagnieżdżone w dokumentach HTML obiekty Java, JavaScript, Flash i inne są powszechne.
Z drugiej strony, choć w dokumentacjach wszystkich testowanych przeglądarek można znaleźć sformułowanie typu "zgodna z HTML 4.01", należy pamiętać, że żadna istniejąca przeglądarka nie obsługuje w pełni standardu HTML 4.01. I nic dziwnego -- w specyfikacji tej określono bardzo wiele elementów i atrybutów, których implementacja jest trudna lub wręcz niemożliwa (no bo do czego mogą się przydać atrybuty lang i dir w znaczniku <hr>?). Są też atrybuty, elementy i style przeznaczone dla agentów niewizualnych, przystosowanych dla osób niepełnosprawnych.
Takiej "pełnej zgodności" nikt zresztą nie chce -- idealnie standardowa przeglądarka odmówiłaby przetworzenia przynajmniej połowy istniejących stron WWW ze względu np. na błędne zagnieżdżania. Rozdziału pomiędzy ideałem a stanem rzeczywistym świadomi są także sami twórcy standardu HTML 4.01 -- specyfikacja ta obejmuje trzy definicje DTD, z których "Strict" to właśnie "standard doskonały", a "Transitional" to "standard de-facto" (jest jeszcze "Frames" opisująca dokumenty ramkowe). Definicja "Transitional" nie dopuszcza, oczywiście, błędów składniowych; obejmuje natomiast wiele elementów odziedziczonych po standardzie 3.2 i nie wymaga od autora korzystania wyłącznie ze stylów (jak to jest w "Strict") do określania wyglądu strony.
Tak więc przeglądarka naprawdę zgodna z HTML 4.01 nie istnieje. Możemy co najwyżej powiedzieć, że dana aplikacja jest mniej lub bardziej zbliżona do abstrakcyjnego "agenta użytkownika" opisywanego w specyfikacji konsorcjum W3C. Szczegółowe wyniki przeprowadzonych testów zgodności z HTML 4.01 znajdują się w tabeli 1. W poniższych podpunktach chciałbym jedynie zwrócić uwagę na niektóre fakty związane z poszczególnymi mechanizmami języka HTML.
Największą różnicą pomiędzy wersją 3.2 (poprzednią) a 4.01 (obecną) standardu HTML jest fakt, że w tym ostatnim grubą kreską oddzielono treść od prezentacji. Według obecnej doktryny W3C, HTML ma służyć do znakowania semantycznego tekstu (opisywania rodzaju zawartości), a nie do zmiany jego wyglądu; to drugie działanie jest tylko "efektem ubocznym" i może podlegać różnej interpretacji w przeglądarkach. Zadania precyzyjnego sterowania układem strony i wyglądem powierzono arkuszom stylów CSS.
Doskonałymi przykładami znaczników charakterystycznych dla HTML-a 4.01, opisujących rodzaj zawartości, są <abbr> i <acronym>, zawierające odpowiednio skrót (np. "ul.") oraz akronim (np. "PKO"). Znaczniki te obsługiwane są w pełni przez Operę (wyświetla pełną nazwę w pasku stanu -- pomysłowe!) oraz Mozillę, Galeona i Nautilusa: te trzy przeglądarki po najechaniu myszą na łańcuch opisany takimi znacznikami zmieniają wygląd wskaźnika i wyświetlają małe pole tekstowe z pełną nazwą (zawartość atrybutu title), przy czym tylko pierwsza z nich obsługuje w tym polu tekstowym polskie znaczki; nie ma rozróżnienia pomiędzy oboma znacznikami. Konqueror ogranicza się do pochylenia zawartości <abbr> i dodatkowo pogrubienia <acronym>, ale zupełnie ignoruje niezwykle ważny w tych znacznikach atrybut title. W3 "zna" tylko akronimy, ale również nie potrafi ich rozwinąć (tylko wyświetla je kapitalikami).
Inny znacznik mówiący tylko o treści i pozostawiający sposób wyświetlania producentowi przeglądarki to <code>, który ma zawierać fragment kodu programu. Niemal wszystkie przeglądarki graficzne zgodnie wyświetlają taki fragment czcionką nieproporcjonalną; fontu nie zmienia tylko Konqueror, ale za to powoduje, że tekst nie jest zawijany przy krawędzi okna. Chyba najbardziej intuicyjnym sposobem interpretacji znacznika <code> byłoby połączenie obu tych rozwiązań i ewentualnie w przyszłości dodanie nowych (np. podświetlanie składni, wcięcia bloków funkcji).
Ciekawe i dające duże pole do popisu znaczniki <del> i <ins> jeśli już są obsługiwane, to niestety tylko tak, jak odpowiednio <strike> i <u> (zupełnie ignorowane są atrybuty datetime i cite). Jedynie Lynx, za pomocą słów DEL i INS wyraźnie zaznacza, że tekst jest usunięty albo wstawiony; niestety, jako DEL oznacza on również tekst znaczników <strike> i <s>. A już zupełnie nie wiadomo z jakich pobudek Konqueror przez tekstem usuniętym i wstawionym powoduje przełamanie wiersza.
Mimo dążenia standardu HTML do oddzielenia zawartości od prezentacji, w specyfikacji wciąż istnieje szereg znaczników typowo formatujących (a więc powodujących zmianę wyglądu tekstu, ale bez podtekstu znaczeniowego). W komentarzach do specyfikacji można przeczytać, że znaczniki te mają służyć głównie do wprowadzenia doraźnego formatowania w szczególnych miejscach tekstu; ogólne formatowanie dla całych dokumentów i zbiorów stron należy pozostawić arkuszom stylów.
Jednak autor strony WWW nie może w pełni "zaufać" nawet tym kilku prostym znacznikom formatującym -- nawet jeśli obsługiwane są przez różne przeglądarki, to obsługa ta może być bardzo różna w zależności od konkretnej "marki" i "modelu". Na przykład, każdy kolejny zagnieżdżony znacznik <big> ma powodować zwiększenie wielkości fontu o jeden stopień. Wydaje się, że najbardziej zgodnie z oczekiwaniami interpretuje go Opera; Mozilla, Galeon i Nautilus nie powiększają dalej tekstu po drugim zagnieżdżonym <big>, a Konqueror w ogóle nie obsługuje zagnieżdżania w tym przypadku. Z przeglądarek tekstowych z tym elementem cokolwiek próbuje zrobić tylko Lynx, domyślnie zmieniając jego kolor na żółty.
Popularny znacznik <center> jest obsługiwany identycznie w każdej przeglądarce... prawie. Konqueror nie wyśrodkowuje tekstu względem okna przeglądarki (jak można byłoby się spodziewać), ale względem całej szerokości strony. Linie poziomie (<hr>) są obsługiwane prawie wszędzie (oprócz Linksa), ale z różnymi zestawami atrybutów i różne traktowanymi (np. W3 błędnie interpretuje align). Spróbowałem też błędnej konstrukcji polegającej na umieszczeniu linii w odsyłaczu; prawie wszystkie przeglądarki obsługujące linie potraktowały to tylko połowicznie tak, jak można się spodziewać (kreskę można było kliknąć, ale nie była zaznaczona obramowaniem ani podkreśleniem); Lynx zignorował odsyłacz. Ponadto, Konqueror ma kłopoty z odświeżaniem grubych linii po przesunięciu zawartości okna.
W znaczniku <pre> wszystko powinno być wyświetlane tak, jak zostało wpisane przez autora; dotyczy to również znaków tabulacji -- powinny być wstawiane co 8 spacji. Poprawnie spisują się tutaj wszystkie przeglądarki oprócz Konquerora. W ogóle miałem wrażenie, że testowana przeze mnie wersja Konquerora miała duże kłopoty z rozpoznawaniem, gdzie należy wstawiać czcionkę nieproporcjonalną -- zdawało się, że wszystko próbuje "renderować" fontem ustawionym jako domyślny (a np. po określeniu w stylach Courier był wyświetlany...). Wszystkie przeglądarki obsługują również błędną konstrukcję, jaką jest przełamanie wiersza w ramach bloku <pre> za pomocą <br>.

Lynx w akcji. Przeglądarki tekstowe robią co mogą, żeby jakoś wyrazić to, na co zwykły tekst nie pozwala. Najczęściej w miejsce graficznego formatowania stosuje się różnorodne kolory.
Odsyłacze to podstawowy element wszystkich stron WWW. Wydawałoby się, że ich obsługa powinna być we wszystkich przeglądarkach pełna i taka sama; tak jednak nie jest. Wciśnięcie klawisza Tab powinno powodować przejście do kolejnego "aktywnego" elementu strony, najczęściej odsyłacza; shift+Tab to poprzedni odsyłacz. Mechanizm ten nie działa w Netscape 4.x i w StarOffice; w Operze zastosowano inne skróty klawiszowe (odpowiednio A i Q lub ctrl-dół i ctrl-góra); w Lynksie Tab działa tylko "do przodu", a w Linksie pozostaje sięgnięcie do klawiszy strzałek.
W ogóle na temat klawisza Tab toczy się teraz w gronie programistów Mozilli dyskusja -- czy ma nawigować tylko po elementach formularza, czy po wszystkich "aktywnych" elementach strony (w tym odsyłaczach)? Prawdopodobnie wprowadzony zostanie pierwszy schemat, a do nawigacji po odsyłaczach będą służyły skróty zaczerpnięte z Opery (która, jak twierdzą programiści Mozilli, powinna stanowić wzór "klawiszologii" dla innych przeglądarek).
Tylko Mozilla, Nautilus i Galeon rozumieją atrybut accesskey, pozwalający wybrać konkretny odsyłacz za pomocą umownego skrótu klawiszowego. Kodowanie dokumentu docelowego (atrybut charset) poprawnie rozpoznał tylko Lynx.
Tabele obsługiwane są nadspodziewanie poprawnie i spójnie. To cieszy, bo jak wiadomo tabele zastępują nieistniejące w HTML-u mechanizmy do projektowania układu strony. Bez obaw możemy więc tworzyć wyszukane układy tabelkowe, o zróżnicowanej liczbie kolumn w wierszach, o komórkach z różnymi atrybutami colspan, tabelki z 1-pikselowymi kolumnami i wierszami (do tworzenia "obramowań") oraz tabelki zagnieżdżone. Tylko z tymi ostatnimi problemy pojawiły się w Lynksie (zupełny brak obsługi) oraz w W3 (popsuta obsługa stylów). W ogóle ze stylami należy postępować w tabelach ostrożnie -- zauważyłem, że np. tylko nieliczne przeglądarki (Konqueror, Opera i W3 -- choć ta ostatnia błędnie) poprawnie obsługują dziedziczenie stylu po znaczniku <table>.
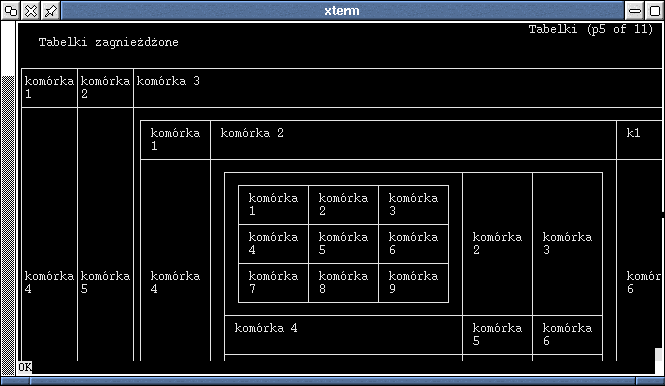
Tabele wcale nie muszą być domeną przeglądarek graficzych. Tekstowy Links radzi sobie z nimi doskonale.
Równie poprawnie obsługiwane są listy -- o ile tylko autor strony nie skorzystał z mniej popularnych atrybutów, takich jak start czy type (mają z nimi kłopoty Konqueror, Opera, Links i W3). Poza tym listy wyświetlane są spójnie w większości przeglądarek, choć bardziej zaawansowane rozwiązania, takie jak zmiana symbolu wypunktowania przy listach zagnieżdżonych, obsługują tylko niektóre programy (przeglądarki "mozillowe", Konqueror i Netscape).
Ramki można lubić albo nie, ale stanowią one część standardu HTML 4.01 i powinny być poprawnie obsługiwane przez przeglądarki. Wszystkie testowane przeglądarki oprócz Lynksa w jakiś sposób potrafią radzić sobie z ramkami. Obsługuje je nawet Links (układa je na kształt tabeli) i W3 (dla każdej ramki tworzy nowy bufor i rozkłada bufory sąsiadująco -- pomysłowe!). Z zagnieżdżaniem ramek (otwarcie zestawu frameset w jednej z ramek) miała problemy tylko Opera (w ogóle nie ładowała kolejnego zestawu frameset) i Links (zagnieżdżanie samo zapętlało się); trochę kłopotów wystąpiło także w Nautilusie, który z ramek wielokrotnie zagnieżdżonych po wciśnięciu "Wróć" powracał natychmiast tak, jakby była to jedna strona. Zwykłe zagnieżdżanie framesetu w jednej z ramek (w celu np. umieszczenia 2 ramek w jednej kolumnie a 3 w drugiej) działa we wszystkich programach. Atrybut frameborder jest obsługiwany wszędzie oprócz Linksa, ale nie wszędzie znaczy to samo (czasem faktycznie brak jest jakiegokolwiek oznaczenia granicy ramki, jak w Konquerorze, a czasem pozostaje szary pasek). Atrybut border, umożliwiający określenie grubości obramowań, obsługują wszystkie graficzne przeglądarki, ale już bordercolor (kolor tego obramowania) nie jest rozpoznawany przez Operę i Konquerora; odstępy pomiędzy ramkami (framespacing) "rozumie" tylko StarOffice.
Ramki zagnieżdżone wewnątrz strony znacznikiem <iframe> nie były obsługiwane tylko przez "netszkapę", Linksa i W3 (ta ostatnia nie potrafiła nawet wyświetlić odsyłacza do zawartości ramki).
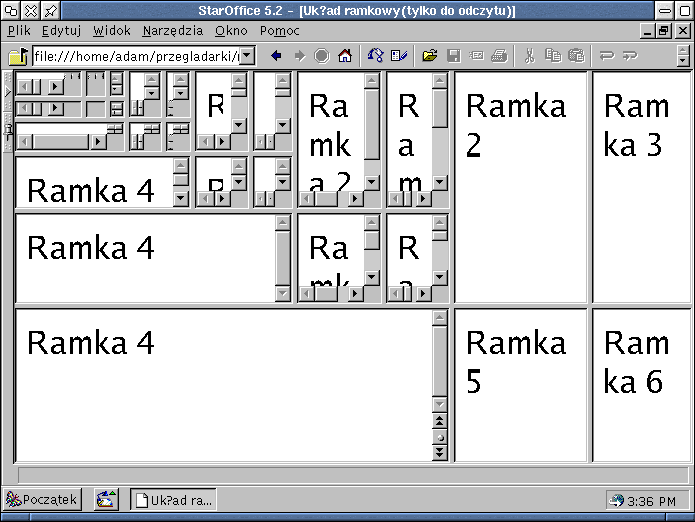
Prawie wszystkie przeglądarki radzą sobie z wielokrotnie zagnieżdżanymi ramkami. Tutaj -- jak to się robi w StarOffice.
Arkusze stylów w mniejszym lub większym stopniu obsługiwane są we wszystkich przeglądarkach; żadna przeglądarka, oczywiście, nie obsługuje wszystkich właściwości CSS. Właściwości nieobsługiwane są w najlepszym wypadku ignorowane, w najgorszym zaś (W3) przypadkowe wartości zostają wyświetlone na ekranie(!). W ogóle cała obsługa stylów jest bardzo niespójna; na przykład, jeśli już obsługiwana jest właściwość border-color i border-width, to brakuje obsługi ogólnego zapisu border (Konqueror i Netscape). Szczegółowe wyniki dotychczas przeprowadzonych testów właściwości CSS można znaleźć w tabeli 2, a selektorów -- w tabeli 3.
We wszystkich przeglądarkach wystąpiły problemy z dziedziczeniem właściwości stylów (szczególnie widoczne jest to w tabelach), przy czym pozytywnie na tym tle wyróżniały się Konqueror i Opera (choć i te przeglądarki czasem "zapominają" o przeniesieniu stylu na element potomny). Najgorsze jest to, że sposób dziedziczenia jest nieprzewidywalny -- na przykład, tabele w Mozilli dziedziczą po elemencie nadrzędnym właściwość font-family, a nie dziedziczą color.
Co ciekawe, nie było natomiast dużych problemów z obsługą stylów określonych dla konkretnego sposobu zagnieżdżenia elementów (np. tylko dla pogrubienia w nagłówku poziomu pierwszego). Tego typu rozwiązań nie obsługiwały tylko Lynx, Links i SO.
Gorzej ze stylami określanymi gdzie indziej niż bezpośrednio w atrybucie style. Jak wiadomo, istnieją trzy dodatkowe sposoby dołączenia stylu: poprzez umieszczenie w nagłówku dokumentu, poprzez atrybut <link> oraz poprzez instrukcję importującą @import. W testowanym zestawie wszystkie trzy metody bezproblemowo obsłużyła tylko Mozilla w wersji 9.1, ale już oparte na wcześniejszych wersjach Nautilus i Galeon -- żadnej z nich! Konqueror obsługiwał style określone w nagłówku i dołączone poprzez <link>, ale już umieszczenie instrukcji @import (przed wszelkimi innymi regułami stylu -- tak wymaga standard) powodowało, że cały arkusz stylu przestawał działać... Niemal wszystkie pozostałe przeglądarki w ogóle nie radziły sobie z tak dołączanymi stylami; ciekawymi wyjątkami były: Lynx (obsłużył tylko @import!) oraz W3 (obsłużyła wszystkie oprócz @import).
Język arkuszy stylów CSS 2 jest bardzo elastyczny. Oferuje między innymi selektory, pozwalające na określenie stylu dla znaczników zagnieżdżonych w konkretnej kolejności (>), występujących jeden po drugim (+) itp. Te nie były poprawnie obsługiwane jedynie przez przeglądarki tekstowe i SO (Netscape nie została przetestowana ze względu na złą obsługę stylów importowanych). Są jednak także selektory specjalne i tutaj z obsługą jest już gorzej: :first-line obsługują tylko przeglądarki "mozillowe" oraz Konqueror i Opera, zaś :first-letter -- tylko Opera. Żadna przeglądarka nie potrafiła określić stylu na podstawie języka (np. div:lang(it)).
Ale specyfikacja CSS daje nam jeszcze więcej możliwości. Na przykład, taka konstrukcja:
ol {counter-reset: liczba}
ol li: before {content: "Element nr " counter(liczba) " ";
counter-increment: liczba}
ol li: after {content: "To był element nr " counter(liczba);}
powinna sprawić, że przed i po każdym elemencie listy uporządkowanej znajdzie się odpowiedni tekst z kolejnym numerem. Tę konstrukcję, pozwalającą także np. automatycznie numerować kolejne akapity czy ilustracje, obsługuje tylko Opera w najnowszej wersji (ostatnia beta zawieszała się po napotkaniu tego zapisu).
Na szczęście powoli mijają już czasy, gdy standard HTML był niedojrzały, a pewni siebie giganci traktowali go jak ladacznicę, z którą zrobić można wszystko. Na nieszczęście, po tym okresie zostały jeszcze niechlubne pamiątki -- znaczniki wymyślone przez producentów w celu zwabienia użytkowników, a najczęściej służące do uzyskiwania tanich efektów na stronach.
Idealnym przykładem jest znacznik <blink>. Powstał za czasów "panowania" NS 4.x, jest przez tę przeglądarkę obsługiwany i właściwie powinniśmy już o nim powoli zapominać; tak przynajmniej wydawało mi się, dopóki nie zacząłem testować przeglądarek. Otóż okazuje się, że przeglądarki oparte na mechanizmie Gecko (Mozilla, Galeon i Nautilus) doskonale obsługują ten niestandardowy znacznik! Naprawdę trudno mi to zrozumieć -- przeglądarki te, nowoczesne i rozwijane przez wspólnoty Open Source, chlubią się największą zgodnością ze standardami, a tymczasem "rozumieją" znacznik nijak nie wynikający ze standardu... Autorzy, szczególnie początkujący, odbierają to jako przyzwolenie na stosowanie znaczników spoza specyfikacji. Uważam, że o wysiłek włożony w implementację <blink> lepiej byłoby poświęcić na przykład na wbudowanie obsługi ciekawego atrybutu cite znaczników <blockquote> i <q> (na razie nie potrafi tego żadna testowana przeglądarka). Na szczęście, w miarę wprowadzania kolejnych wersji twórcy przeglądarek wydają się iść w dobrym kierunku. Inny niestandardowy znacznik, <spacer> jest obsługiwany w wersjach 8 i 9 Mozilli (oraz w opartych na tych wersjach Galeonie i Nautilusie), ale w wersji 9.1 już nie!
Inny przykład: znacznik <comment> to microsoftowy wymysł, który miał działać podobnie jak <!-- ... -->, czyli oznaczać komentarz (tekst nie jest wyświetlany w oknie przeglądarki). Większość testowanych przeglądarek go nie obsługuje i tego można było oczekiwać. Wyjątkiem jest... Lynx. Na szczęście już żadna przeglądarka bez wyjątku nie obsługuje innego "explorerowego" pomysłu <marquee>.
W obsłudze znaczników niestandardowych twórcy przeglądarek bywają też bardzo niekonsekwentni -- dlaczego jeśli już wprowadzono obsługę netscape'owego <nobr> (przeglądarki oparte na Gecko oraz Opera), nie zagwarantowano jednocześnie obsługi ściśle związanego z nim <wbr>? Dlaczego jeśli już obsługiwany jest niezalecany <xmp>, to niepoprawnie? Tekst <xmp> powinien być zawijany jak na terminalu 80-kolumnowym, a znaki <, > itd. nie powinny być interpretowane jako specjalne (to ostatnie obsługuje tylko SO, NS i Lynx); Opera w ogóle ma zepsutą obsługę tego znacznika -- po przełamaniu wiersza <br> czcionka przełącza się do proporcjonalnej.
Ogromna większość stron WWW tworzona jest przez amatorów, często nawet nie mających pojęcia o HTML-u, a korzystających z automatycznych generatorów i edytorów WYSIWYG. Nic dziwnego, że naprawdę mało jest stron, na których nie ma błędów składniowych. Należy pamiętać, że o ile liczba możliwych (rozsądnych!) kombinacji i zagnieżdżeń znaczników HTML jest jeszcze policzalna, o tyle liczba możliwych błędów na stronach WWW i kontekstów, w jakich występują jest nieskończona, a więc nigdy nie powstanie przeglądarka "przetestowana do końca". Na potrzeby tego artykułu stworzyłem celowo tylko kilka błędnych i w ogóle absurdalnych zapisów HTML -- chciałem zobaczyć, jak poradzą sobie z nimi testowane programy.
Jeśli odsyłacz do etykiety wewnątrz dokumentu prowadził w dwa miejsca (np. dwie etykiety #ostrzezenie), to większość przeglądarek odsyłała do pierwszego wystąpienia etykiety. Opera, Netscape, Links i W3 -- do ostatniego.
Dokument nie zawierający znaczników <html>, <body>, <frameset> ani <head>, a jedynie rozszerzenie .html, był traktowany różnie: Mozilla z Operą i W3 "widziały" go jak zwykły dokument HTML; Konqueror też, ale wyświetlał zawartość komentarza; Netscape, Links i SO nie wyświetlały komentarza, ale za to pokazywały cały znacznik <a href...>, a Lynx w ogóle zaprzestał wyświetlania dokumentu po jednym z kolejnych znaczników. Kiedy dla odmiany załadowałem dokument z wieloma znacznikami <body>, nastąpiło zamieszanie innego rodzaju: Mozilla, Konqueror, Netscape, SO i Opera wyświetlały zawartość wszystkich z nich, a pobierała kolor tła z pierwszego znacznika; W3 wyświetlała tekst na tle różnych kolorów, w zależności od bieżącego znacznika <body>. Ponadto, W3 i Opera wstawiały po każdym <body> znak nowego wiersza.
Dla wielu osób przeglądarka WWW to nie tylko program do sporadycznego "kontaktu ze światem", ale narzędzie pracy włączone na którymś pulpicie przez cały dzień i wykorzystywane niemal odruchowo -- tak jak kalkulator czy edytor tekstów. Dlatego ogromne znaczenie ma wygoda użytkowania przeglądarki, na którą składa się bardzo wiele elementów; przyjrzyjmy się teraz niektórym z nich.
Przede wszystkim nawigacja! Z podstawowymi funkcjami "wędrowania po pajęczynie" w większości przeglądarek nie ma problemu i niemal wszędzie da się nawigować bez użycia myszy. Szkoda tylko, że nie ma jednego, ustalonego zestawu skrótów klawiszowych. Na przykład, aby wprowadzić nowy adres do surfowania, w Mozilli wciskamy ctrl+shift+l; w Konquerorze i Galeonie ctrl+o; w Operze F3 (dokładnie odwrotnie niż w Galeonie); w SO ctrl+o (tak, wystarczy w polu nazwy pliku wpisać adres rozpoczynający się od http://); w Lynksie i Linksie klawisz g; a w W3 ctrl+o. Co ciekawe, w Galeonie, który według autorów ma służyć "do przeglądania WWW i niczego więcej", nie udało mi się znaleźć skrótów klawiszowych pozwalających na przejście wstecz lub w przód; nie znalazłem ich także w SO. Poza tym wędrowanie po stronach realizowane jest najczęściej za pomocą strzałek + ewentualnie klawisz Alt; tylko w Nautilusie odpowiednie klawisze to ctrl+] i ctrl+[, a w W3 -- B i F. Tylko Nautilus, Konqueror, W3 ... umożliwiają przejście o poziom w górę w strukturze katalogów serwera (bardzo wygodna funkcja), natomiast większość przeglądarek udostępnia skrót klawiszowy pozwalający na przekształcenie bieżącego adresu (często jest to ten sam klawisz, który służy do wprowadzania nowego adresu, ale nie zawsze -- patrz Lynx i Links).
W ogóle za skróty klawiszowe największe brawa należą się Lynksowi. Oczywiście, przeglądarki tekstowej nie da się obsługiwać inaczej niż "palcami", ale w Lynksie -- jak nigdzie indziej -- przypisano klawisze bardzo wielu, nawet najbardziej wyszukanym funkcjom. Na przykład, klawisz V umożliwia wyświetlenie listy odsyłaczy odwiedzonych w czasie bieżącej sesji, ctrl+k przejrzenie uzbieranych ciasteczek, a # -- przejście do nagłówka nawigacyjnego strony. Zestaw skrótów w Linksie jest już dużo uboższy, a do wykonania wielu funkcji konieczne jest otworzenie menu. Dużo przydatnych klawiszy obsługuje także W3; duża część z nich odpowiada domyślnym emacsowym skrótom służącym do poruszania się po dokumencie tekstowym, a inne zaczerpnięto z przeglądarki dokumentacji Info. Spośród przeglądarek graficznych, klawiatura stanowczo najlepiej została wykorzystana w Operze (o czym wspomniano już wcześniej) -- bardzo bogaty zestaw skrótów nawigacyjnych, a także sporo skrótów rzadziej spotykanych (np. g przełącza pomiędzy trybami wyświetlania grafiki, a ctrl+g pomiędzy stylem wyświetlania określonym przez autora dokumentu a tym zdefiniowanym przez użytkownika).
W Operze, w Lynksie i w Linksie stosunkowo najprościej można dowiedzieć się, jakie skróty klawiszowe zostały do czego przypisane (np. w Lynksie wystarczy wcisnąć k, a w Operze ctrl+b). Konia z rzędem temu, kto znajdzie listę klawiszy dla Mozilli (które, notabene, zmieniły się od wersji 0.8) -- mnie udało się wyszukać tylko pliki źródłowe XML odpowiedzialne za przypisania (dla zainteresowanych: http://lxr.mozilla.org/seamonkey/find?string=bindings).
Ale nawigacja to nie tylko klawisze. Mnie bardzo istotna wydaje się możliwość powrotu do tego samego miejsca poprzedniej strony (a nie do jej początku) po wciśnięciu "back" lub odświeżeniu. Nie wszystkim przeglądarkom zawsze się to udaje -- kłopoty zdarzają się w przeglądarkach opartych na Gecko. Nautilus natomiast nie zmienia koloru odwiedzonych odsyłaczy -- to także duża niedogodność. Podobne zaniedbanie występuje w Lynksie i Linksie; a przecież W3, choć także "tekstowa", potrafi to robić. W testowanym Konquerorze zauważyłem również błąd polegający na tym, że po pewnym czasie "surfowania" wskaźnik przestawał zmieniać się na "łapkę" po najechaniu na odsyłacz. Ten sam Konqueror udostępnia jednak funkcję, której brakuje wszystkim innym zawodnikom: najechanie na "link" powoduje wyświetlenie wielkości dokumentu docelowego w pasku stanu.
Bardzo przydatna bywa możliwość powiększania/pomniejszania czcionki dokumentu lub przybliżania/oddalania całego dokumentu. Odpowiednie klawisze na pasku narzędzi lub skróty klawiszowe oferują: Mozilla, Galeon, Konqueror, Opera, SO. Jeszcze inna ważna funkcja to wyświetlanie kodu źródłowego strony. Nie udało mi się jej znaleźć tylko w Nautilusie. W pozostałych przeglądarkach zastosowano różne podejścia: albo źródło wyświetlane jest z zastosowaniem własnych mechanizmów (Mozilla, Netscape, Lynx i Links), albo poprzez zewnętrzne programy (np. Konqueror wykorzystuje KWrite, a Opera xedit; ta ostatnia umożliwia zmianę programu obsługującego). Co ciekawe, mimo zdefiniowanego automatycznego włączania kolorowania składni w Xemacsie, po "podejrzeniu" źródła w W3 (w3-source-document) konieczne było ręczne wywołanie polecenia font-lock-mode.
Aby aplikacje Javy dawało się uruchamiać z poziomu przeglądarek, najpierw w systemie musi być udostępnione środowisko uruchomieniowe Javy (ang. Java Runtime Environment). Istnieją implementacje JRE różnych producentów; najpopularniejsze to: Blackdown (http://www.blackdown.org), IBM (http://www.ibm.com/developer/java), Sun (http://java.sun.com/products).
Najprostszym sposobem sprawdzenia, czy obsługa Javy działa w danej przeglądarce jest załadowanie strony do konfiguracji JRE, znajdującej się w katalogu zainstalowanego środowiska (np. /usr/local/j2re1.3/).
Większość przeglądarek posiada opcję wyświetlania konsoli Javy w czasie uruchamiania apletów. Warto ją zaznaczyć, szczególnie w czasie pierwszych testów Javy; na konsoli wyświetlanych jest wiele dodatkowych komunikatów debuggera, przydatnych przy rozwiązywaniu problemów.
Po zainstalowaniu środowiska uruchomienowego i wirtualnej maszyny Javy instalacja sprowadza się do stworzenia dowiązań symbolicznych do wtyczki javaplugin.so w katalogach plugin obu przeglądarek. Na przykład:
# cd /usr/lib/netscape/plugin # ln -s /usr/local/j2re1.3/plugin/i386/javaplugin.so # cd /usr/lib/mozilla/plugin # ln -s /usr/local/j2re1.3/plugin/i386/javaplugin.so
W obu przeglądarkach obecność wtyczek można zweryfikować (oprócz sposobu podanego wyżej dla wszystkich przeglądarek) poprzez wybranie z menu Pomoc (lub Help) pozycji About Plugins.
Obsługa Javy w Konquerorze realizowana jest poprzez serwer apletów KJAS. Aby udostępnić środowisko uruchomieniowe dla apletów Javy w Konquerorze, wybieramy Ustawienia -> Configure Konqueror -> Przeglądarka WWW Konquerora -> Java -> Enable Java globally.
Opera w wersji linuksowej obsługuje język JavaScript, ale Javy jeszcze nie. Według producenta, obsługa Javy oraz wtyczek Netscape ma być uruchomiona lada chwila.
Po rozpakowaniu pakietu flash_linux.tar.gz pobranego ze strony http://www.macromedia.com należy skopiować pliki ShockwaveFlash.class oraz libflashplayer.so do katalogów plugins przeglądarek Mozilla i Netscape i ponownie uruchomić przeglądarki. Działanie wtyczki można sprawdzić na przykładowych stronach wymienionych pod adresem http://www.macromedia.com/showcase/. Opera dopiero ma obsługiwać wtyczki typu Netscape -- wtedy też będzie można korzystać z Flasha pod tą przeglądarką. Konqueror już teraz potrafi korzystać z wtyczek Netscape; w dystrybucji Mandrake 8.0 wymagało to jednak doinstalowania pakietu kdebase-nsplugins i zrestartowania KDE (a nie tylko Konquerora).
Przeglądarki są tak różne, jak różne są cele, do których je się wykorzystuje. Na jednym krańcu stoją programy pracujące w trybie tekstowym, stosowane najczęściej do czytania dokumentacji, artykułów naukowych itd. Na drugim -- zintegrowane z pulpitem i środowiskiem graficznym kombajny multimedialne, w których przeglądanie stron WWW to tylko jedna z wielu funkcji. Pamiętajmy, że aby jakakolwiek ocena mogła być sprawiedliwa, nie może być ona oderwana od celów i wymagań, jakie stawia się przed programem.
Trudno więc byłoby wytypować "pierwsze" albo "ostatnie miejsce". Wszystko zależy nie tylko od tego, czego oczekujemy, ale również od zupełnie osobistych preferencji; sprawiedliwa ocena wymagałaby ponadto o wiele większej liczby testów, niż przeprowadziłem dotychczas, a także szerszego zestawu testowego (to, że dana cecha nie działa na jednej stronie testowej, nie znaczy jeszcze że nie działa w ogóle). Jeśli chodzi o obsługę elementów i atrybutów najnowszej specyfikacji HTML, wydaje się zwyciężać Mozilla i korzystające z niej Galeon z Nautilusem. W obsłudze stylów CSS niemal dorównuje jej Opera. Ale już na pewno palmę pierwszeństwa należałoby oddać Operze, jeśli oceniać łatwość obsługi, skróty klawiszowe i dostępną pomoc. Niestety, Opera jako jedyna nie obsługuje polskich ogonków (mimo zapewnień producenta, że z obsługą znaków międzynarodowych wszystko jest OK); to praktycznie dyskwalifikuje ją w polskim zakątku globalnej wioski.
Z przeglądarek tekstowych obsługa standarów równo "rozkłada się" pomiędzy Lynksa i Linksa. Links zjednuje sobie użytkowników umiejętnością interpretacji tabel i ramek; ale stary Lynx stanowczo zwycięża "na klawisze" i na łatwość obsługi. W3 niby dorównuje obu tekstowym rywalom w standardach, a nawet lepiej obsługuje style, z drugiej jednak strony to stanowczo najsłabiej dopracowana przeglądarka ze wszystkich testowanych -- zdarza się, że wyświetla fragmenty kodu źródłowego strony, a niejednokrotnie można nawet przez nią przegapić ważne informacje, bo bywa, że wyświetla czarny tekst na czarnym tle...
Osobiście na silnym sprzęcie regularnie korzystam z Mozilli i czasem z Konquerora; na słabym -- z Opery i z Lynksa. Gdybym korzystał z Gnome, prawdopodobnie cały czas miałbym pod ręką Nautilusa; do szybkiego i poprawnego załadowania strony i niczego więcej może się przydać Galeon. Przeglądarka StarOffice to dość osobliwa aplikacja w tym towarzystwie -- wymaga, jak cały pakiet, bardzo silnego sprzętu, a przy przeglądaniu stron WWW odnosi się niemiłe wrażenie, że to dokumenty Worda; integracja z pakietem biurowym stanowiła jednak wyznacznik przy projektowaniu tej przeglądarki -- a to zadanie wypełniono w stu procentach. Netscape 4.x, choć wciąż poprawiane są jej błędy, wydaje się powoli odchodzić w niepamięć; Lynx i Links -- mimo tekstowego interfejsu -- trzymają się świetnie i pewnie jeszcze długo nie zejdą z pola bitwy. Stosunkowo najdalszą drogę ma przed sobą W3, ale to przecież program wyjątkowy -- w końcu jest tylko częścią zwykłego (khm...) edytora tekstów.
Plus albo komentarz oznacza cechę/atrybut/znacznik rozpoznawany przez przeglądarkę, a minus -- nierozpoznawany. Puste komórki oznaczają, że danej cechy nie przetestowano. Minus niekoniecznie oznacza, że przeglądarka w ogóle "nie rozumie" danej właściwości (choć prawdopodobnie tak właśnie jest); w ten sposób zaznaczyłem jedynie, że nie udało mi się znaleźć jakiegokolwiek dowodu obsługi tego elementu. Na przykład, standard nie wymaga, aby znacznik <dfn> powodował jakiekolwiek zmiany formatowania; przeglądarka może go wykorzystać do tworznia listy definicji zawartych w tekście, glosariusza itp.
Tabele zawierające dane o tym, co obsługują współczesne przeglądarki linuksowe:
Do testowania użyłem własnoręcznie stworznego zestawu testowego, który oczywiście nie jest doskonały i który wcale nie musi dawać miarodajnych wyników. Jeśli wpadłeś na pomysł dodania nowych testów -- zapraszam do aktualizacji i podsyłania na mój adres Zapraszam także do aktualizacji istniejących tabel -- a może także dodanie do nich nowych przeglądarek?.
A tu inne znalezione w sieci zestawy testowe (także one czasami były wykorzystywane do sprawdzenia niektórych funkcji przeglądarek):