



Na stronach Słupskiej Grupy Użytkowników Linuksa pojawił się ciekawy artykuł poświęcony działaniu i konfiguracji DNSów. Dzięki uprzejmości autora, publikujemy go na łamach 7thGuarda. Zapraszamy do lektury…
Domain Name System – działanie i konfiguracja usługi
Korzenie Internetu sięgają eksperymentalnej sieci komputerowej łączącej organizacje badawcze, zwanej ARPAnet. W latach siedemdziesiątych minionego stulecia siec ARPAnet liczyła zaledwie kilkaset hostów. Wraz z momentem kiedy opracowany na Uniwersytecie Kalifornijskim w Berkeley zestaw protokołów TCP/IP stal się standardowym protokołem w ARPAnecie oraz gdy dołączono go do systemu Unix BSD łączność z ARPAnetem stała się dostępna dla wielu organizacji. Sieć rozrosła się do tysięcy hostów. Człowiek nie jest maszyną dlatego też w przeciwieństwie do nich łatwiej mu zapamiętywać nazwy niż cyfry. Tak oto powstał plik HOSTS.TXT przechowujący odwzorowania nazw komputerów ARPAnetu na adresy IP. Plik ten redagowało Centrum Informacji Sieciowej (NIC) w Instytucie Badawczym Stanforda, a rozpowszechniany był z hosta SRI-NIC. Jak łatwo się domyślić takie rozwiązanie spowodowało iż wraz ze wzrostem liczby hostów rosła wielkość pliku, a co ważniejsze zwiększył się ruch w sieci powodowany ciągłym uaktualnianiem tego pliku. Obciążenie hosta SRI-NIC zbliżało się do wartości krytycznej tego było zbyt wiele… W 1984 roku Paul Mockapetris wydaje dokumenty RFC 882 i 883 opisujące domenowy system nazw (DNS).
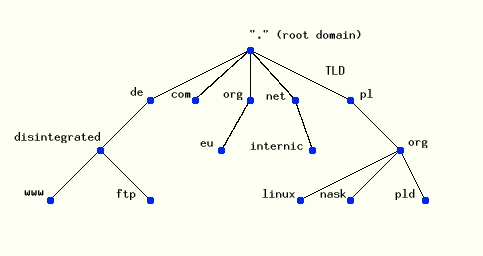
DNS to rozproszona baza danych. Dzięki takiemu rozwiązaniu możliwe jest lokalne zarządzanie fragmentami całej bazy, udostępnianie danych realizowane jest za pośrednictwem mechanizmu klient-serwer. Resolwer (klient) tworzy zapytanie DNS i wysyła je do serwera DNS. (Więcej na ten temat w następnych rozdziałach). Struktura DNS jest strukturą drzewiastą na szczycie tej struktury znajduje się węzeł główny (root domain – domena główna) oznaczany etykieta pustą „” (zapisywany jako kropka). Kolejnym elementem tego drzewa są tzw. TLD (Top Level Domains) czyli domeny najwyższego rzędu np: com, pl, edu, gov, mil, de itp. Za przyporządkowanie nazw hostów na niższych szczeblach hierarchii (poniżej TLD) odpowiada organizacja NIC każdego kraju. Dlatego spotykamy np domeny typu edu.pl, com.pl, org.pl. Jednakże taka organizacja nie jest regułą ani obowiązkiem czego przykład stanowi organizacja domen niższych poziomów w Niemczech, gdzie nazwy domenowe odnoszą się bezpośrednio do firm. Struktura drzewiasta uniemożliwia dublowanie się nazw hostów czy poddomen. Nie można utworzyć w jednej domenie dwóch poddomen o takich samych nazwach tak samo jak niemożliwością jest stworzenie w tym samym katalogu dwóch podkatalogów identycznie się nazywających.
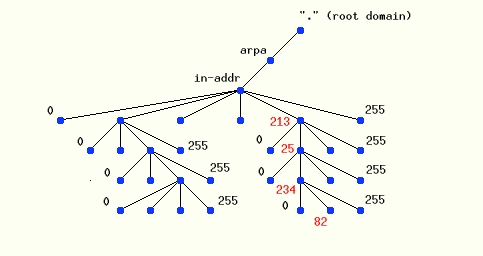
RevDNS to odwzorowywanie adresów IP na nazwy. W przestrzeni nazw domenowych istnieje domena in-addr.arpa, węzły w tej domenie są etykietowane wg liczb w kropkowej notacji adresu IP. Wynika z tego prosty wniosek, że domena in-addr.arpa posiada 256 węzłów, których etykietą jest pierwszy oktet adresu IP. Każdy z tych węzłów rozgałęzia się na kolejne 256 węzłów których etykietą jest już drugi oktet adresu IP. Tworzy się w ten sposób drzewo posiadające cztery poziomy (tyle ile jest oktetów w adresie IP). Pełna struktura została pokazana na rysunku poniżej. W ten sposób domena in-addr.arpa w rzeczywistości może pomieścić wszystkie adresy IP Internetu. Należy jeszcze dodać, że adresy w nazwie domenowej zapisywane są od tylu – adresowi IP 213.25.234.82 odpowiada węzeł w domenie in-addr.arpa 82.234.25.213.in-addr.arpa (jak pokazano na rysunku). Taka struktura umożliwia delegowanie domen w strefie odwzorowywanie odwrotnego.
Programy potrzebujące nazw z przestrzeni nazw domenowych (np. ftp) posługują się resolwerami. Resolwer odpytuje serwer nazw, następnie interpretuje otrzymaną odpowiedź i ostatecznie zwraca informacje do programu, który ich zażądał. Większość pracy związanej ze znalezieniem odpowiedzi wykonuje serwer DNS. Większość resolwerów jest określanych przez specyfikacje DNS jako resolwery szczątkowe gdyż nie potrafią nawet buforować otrzymanych odpowiedzi (robi to serwer DNS).
Konfiguracja resolwera jest bardzo prosta, przechowuje ją plik resolv.conf w katalogu /etc. Przykładowa zawartość tego pliku:
nameserver 194.204.159.1 nameserver 194.204.152.34
Dyrektywa nameserver informuje resolwer o tym z jakich serwerów DNS ma korzystać, host, który świadczy usługi nazewnicze nie musi mieć dyrektywy nameserver, ponieważ resolwer domyślnie szuka serwera nazw na hoście, w którym działa.
- Rekurencyjne
- – to zapytanie wysyłane jest głownie przez resolwery (blokuje się obsługę zapytań rekurencyjnych od innych serwerów DNS). Gdy serwer otrzymuje zapytanie rekurencyjne zostaje obarczony odpowiedzialnością za dostarczenie odpowiedzi. Serwer powtarza te sama procedurę tzn. wysyła zapytanie do innego serwera, który udziela mu wskazania, pytający podąża za wskazaniami aż do otrzymania ostatecznej odpowiedzi, którą może być komunikat o błędzie.
- Iteracyjne
- – to zapytanie jakie wysyłają sobie serwery DNS. Serwer DNS zwraca pytającemu najlepszą odpowiedź jaką posiada czyli wskazanie (adresy serwerów DNS bliższych domenie, o którą otrzymał zapytanie) pytający sam wybiera, jedno ze wskazań.
W tym rozdziale dowiesz się jak przebiega proces odnalezienia adresu IP w przestrzeni nazw. Powiedzmy, że chciałbyś znaleźć adres IP hosta antifa.zoltan.eu.org. Twój resolwer wysyła do serwera dns zapytanie rekurencyjne. Serwer nic nie wie o tej strefie więc odpytuje serwery główne czy wiedzą coś na temat tej domeny. Serwery główne oczywiście bezpośrednio też o niej nic nie wiedzą ale za to zwracają mu wskazanie do serwerów przechowujących dane o domenie org. (jak juz powinieneś zauważyć nasz serwer wysłał zapytanie iteracyjne) Nasz serwer DNS wybiera spośród tych wskazań i odpytuje jakiś serwer domeny org. Ten z kolei zwraca mu listę serwerów odpowiedzialnych za domenę eu.org. Serwery eu.org ponownie zwracają wskazanie informujące o tym kto odpowiada za domenę zoltan.eu.org. I tym razem nasz serwer podąża za wskazówką i odpytuje serwer domeny zoltan.eu.org, ten serwer przegląda swoją bazę danych i stwierdza ze taki host ma adres 212.160.112.227.
Może wydawać się że cały ten proces jest dość skomplikowany i długotrwały, w rzeczywistości odbywa się to zupełnie szybko dzięki mechanizmowi zwanemu buforowaniem. W poprzednim paragrafie dowiedziałeś się, że serwer otrzymuje wiele wskazań do innych serwerów nazw, serwer nie zapomina o nich, a wręcz przeciwnie gromadzi je by przyspieszyć odwzorowanie. Następnym razem kiedy chciałbyś znowu dowiedzieć się jaki adres ma host antfa.zoltan.eu.org serwer najpierw przeszukałby swoja pamięć podręczną, w której natrafiłby na tą nazwę i natychmiastowo udzieliłby odpowiedzi. Co więcej, gdybyśmy zapytali teraz o IP hosta tychy.eu.org to serwer DNS przeszukując pamięć podręczną natrafiłby na informację, że dane o tej domenie posiada ns.eu.org (zbuforował tą informację wykonując poprzednie wyszukiwanie) i bezpośrednio jego zapytałby o IP hosta tychy.eu.org. Oczywiście serwer DNS nie buforuje danych w nieskończoność, czas jaki serwer ma przechowywać daną informacje jest określany w pliku konfiguracyjnym dla danej strefy i nazywany jest ttl (time to live). Po upływie tego czasu dane są kasowane z pamięci podręcznej.
Paul Mockapetris był pierwszą osobą, która napisała realizacje systemu nazw domenowych nosiła ona nazwę JEEVES. Późniejsza implementacją był program BIND (Berkeley Internet Name Domain) autorstwa Kevina Dunlapa dla systemu Unix BSD. Program BIND jest najpopularniejszą implementacją DNS został przeniesiony do praktycznie wszystkich odmian Uniksa i Linuksa. Jego popularność jest tak ogromna, że został nawet przeniesiony na platformę Windows NT firmy Microsoft.
Aby system nazw domenowych był bardziej niezawodny przyjęto, że powinno uruchamiać się conajmniej dwa serwery nazw. Jeden z tych serwerów to tzw. Primary DNS (master), natomiast drugi to Secondary DNS (slave). Różnica między nimi jest taka, że pierwszy wszystkie dane o strefach posiada zapisane na dysku i każda zmiana strefy dokonywana jest na tym serwerze. Serwer zapasowy (slave) w regularnych odstępach czasu pobiera pliki stref od swojego mastera (proces ten nazywa się transferem stref). Istnieje jeszcze możliwość skonfigurowania serwera nazw, który nie posiada żadnych plików stref (nie posiada zwierzchności nad żadną domeną) taka konfiguracja jest bardzo przydatna, gdyż potrafi wykonywać zapytania DNS dla aplikacji działających w sieci lokalnej i co najważniejsze przechowywać je w pamięci podręcznej. Konfiguracja ta nosi nazwę serwera pamięci podręcznej (caching-only server) i jest najprostsza do zrealizowanie z punktu widzenia administratora. Konfiguracja wspomnianych wyżej serwerów nazw zostanie omówiona poniżej.
Rozdział ten, w którym omawiać będziemy tworzenie pliku named.conf jest dobrym miejscem, aby omówić wspomniane wyżej konfiguracje Bind’a, gdyż właśnie w tym pliku zapada decyzja o funkcjach jakie będzie spełniał ten program. Chciałbym zaznaczyć, że program Bind może równocześnie spełniać wszystkie funkcje, o których wspomniałem w poprzednim paragrafie tzn. może być podstawowym serwerem dla jednej domeny, zapasowym dla drugiej i oczywiście buforować wszystkie zapytania. W tej chwili może się to wydawać trochę niezrozumiałe ale w miarę jak będziemy budować plik konfiguracyjny powinno stać się jasne.
Przejdźmy więc do konfiguracji. Dozwolone są trzy rodzaje komentarzy:
# w stylu powłoki systemu // jak w C++ /* jak w C */
Rozpoczniemy od określenia kilku opcji globalnych:
// Każda instrukcja musi kończyć się średnikiem options { directory "/var/named" ; //Ustawia katalog roboczy serwera auth-nxdomain yes; //Dzięki tej opcji wszystkie negatywne odpowiedzi jakie //zbuforował serwer będą traktowane jako autorytatywne //tzn jeżeli serwer udzieli innemu informacji //o tym, że dany host nie istnieje w domenie, nad którą nie mamy //zwierzchnictwa to pytający uzna nasza odpowiedź za autorytatywną listen-on {any;}; // Opcja, dzięki której serwer DNS będzie nasłuchiwał // na wszystkich interfejsach pid-file "named.pid"; // Ścieżka do pliku przechowującego numer procesu named, // względem tej ustawionej w dyrektywie directory };
Jak wynika z poprzednich paragrafów serwer, aby mógł działać musi posiadać wskazania do serwerów głównych. Wskazania te znajdują się w pliku named.root lub named.cache, który dostępny jest z serwera ftp.rs.internic.net. W obecnej chwili na całym świecie jest trzynaście serwerów głównych. Teraz musimy poinformować nasz serwer DNS o tym gdzie znajduje się informacja o tych serwerach za pomocą następującej dyrektywy:
zone "." IN { type hint; file "named.root"; };
Opcja file jest lokacja pliku względem ścieżki ustawionej w directory. Podobnie musimy dodać pliki dla pętli zwrotnej, której każdy host używa do komunikacji z samym sobą. Serwer mógłby działać poprawnie i bez konfiguracji pętli zwrotnej, ale jeśli główny serwer nazw nie byłby skonfigurowany do odwzorowywania tego adresu to jego wyszukiwanie mogłoby zakończyć się niepowodzeniem, najlepiej jest zapewnić to odwzorowywanie samemu co też uczynimy za pomocą znanej już dyrektywy.
//odwzorowanie normalne zone "localhost" IN { type master; file "db.localhost"; }; //odwzorowanie odwrotne zone "0.0.127.in-addr.arpa" IN { type master; file "db.127.0.0"; };
Zawartość plików db.localhost oraz db.127.0.0 zostanie pokazana w rozdziale dotyczącym tworzenia stref, aby nie wprowadzać zamieszania. Do tego momentu zawartość pliku named.conf wspomnianych w poprzednich rozdziałach konfiguracji serwera DNS jest wspólna. Należy dodać, że tak skonfigurowany serwer DNS jest juz w pełni działającym serwerem pamięci podręcznej.
My jednak nie chcemy, aby nasz serwer DNS spełniał tylko taką rolę. Mamy przecież domenę, którą chcemy zarządzać. Dodajmy więc wpisy informujące nad jaka domeną mamy zwierzchność.
Jeżeli konfigurujemy podstawowy serwer DNS
//odwzorowanie normalne zone "zoom.pol" IN { type master; file "db.zoom.pol"; }; //odwzorowanie odwrotne zone "0.168.192.in-addr.arpa" IN { type master; file "db.192.168.0"; };
Jeżeli konfigurujemy zapasowy serwer DNS
//odwzorowanie normalne zone "zoom.pol" IN { type slave; masters { 192.168.0.1; }; file "bak.zoom.pol"; }; //odwzorowanie odwrotne zone "0.168.192.in-addr.arpa" IN { type slave; masters { 192.168.0.1; }; file "bak.0.168.192"; };
Kilka słów komentarza – opcja masters to lista serwerów podstawowych, od których można pobrać informacje o strefie; opcja type informuje o rodzaju serwera nazw(podstawowy lub zapasowy); opcja file (dla master) to ścieżka do pliku, w którym zawarte są informacje o domenie; opcja file (dla slave) pokazuje ścieżkę do pliku, w którym serwer zapasowy zapisze ściągnięte informacje. Serwer zapasowy podczas pracy przechowuje te informacje w pamięci. Opcja ta nie jest niezbędna lecz zalecam jej stosowanie. Dlaczego ? – to prosty przykład: Przypuśćmy nasz serwer zapasowy działa, pobrał już dane o jakiejś strefie i zapisał je do pliku. Nagle przestaje działać serwer podstawowy tej strefy, a my musimy zrestartować nasz serwer zapasowy. Jak wiadomo przy starcie serwery zapasowe łączą się z podstawowymi by pobrać dane, ale w tym przypadku byłoby to niemożliwe bo serwer podstawowy nie działa. My nie mamy się czym martwić w tej sytuacji nasz serwer zapasowy przeczyta dane z pliku, będzie próbował się dalej łączyć z serwerem głównym i dalej będzie w pełni spełniał rolę serwera zapasowego. Gdybyśmy nie posiadali tego pliku serwer zapasowy nie miałby źródła danych, a co za tym idzie nie odpowiadałby na zapytania dotyczące tej domeny. Proszę sobie wyobrazić jakie to ma skutki jeżeli posiadamy tylko jeden serwer podstawowy i jeden zapasowy.
I to w zasadzie koniec podstawowej konfiguracji pliku named.conf. O kolejnych opcjach związanych z logowaniem, bezpieczeństwem i narzędziami usprawniającymi prace z serwerem DNS dowiesz się w następnych rozdziałach. Teraz pora by w końcu poznać budowę plików stref, tych plików, które umieszczałeś w dyrektywie zone w opcji file dla Twojej domeny…
…naukę tą rozpoczniemy od rekordu SOA, który znajduje się w każdym pliku strefy. Komentarze w pliku strefy poprzedza się znakiem średnika.
Postać rekordu SOA
domain.pl. IN SOA dns1.domain.pl. hostmaster.domain.pl. ( 2002081401 ;SERIAL 3h ;REFRESH 1h ;RETRY 1w ;EXPIRE 1h ) ;MINIMUM
A teraz czas na wyjaśnienie wszystkich wartości w tym rekordzie.
domain.pl. – nazwa domeny, dla której jesteśmy serwerem
IN – klasa rekordu (podana wartość dla sieci TCP/IP)
SOA – typ rekordu
dns1.domain.pl. – nazwa podstawowego serwera DNS dla naszej domeny
hostmaster.domain.pl. – adres kontaktowy email do osoby odpowiedzialnej za strefę (pierwsza kropkę należy traktować jako znak @ (at))
SERIAL – wartość dla zapasowego serwera DNS, przy każdej zmianie w strefie w serwerze podstawowym należy zwiększać tę wartość, gdyż sprawdzając aktualność swoich danych serwer podstawowy porównuje numer, którym obecnie dysponuje z numerem, który właśnie pobrał, w momencie, gdy pobrany numer jest większy zostaje rozpoczęty transfer całej strefy. Wg mnie najlepszy format numeru seryjnego to taki jaki podano w przykładzie YYYYMMDDNN, gdzie YYYY – rok, MM – miesiąc, DD – dzień, NN – numer modyfikacji danego dnia.
REFRESH – informacja dla serwera zapasowego co jaki czas ma sprawdzać aktualność swoich danych strefowych
RETRY – jeżeli nie udało się połączyć z serwerem podstawowym po upływie czasu odświeżania (np. awaria łącza w sieci, w której pracuje serwer podstawowy) to w tym polu znajduje się informacja dla serwera zapasowego co ile ma ponawiać próbę nawiązania połączenia
EXPIRE – czas po jakim serwer zapasowy uzna dane w strefie za nie aktualne, jeżeli nie zdoła się połączyć z serwerem podstawowym po okresie czasu zdefiniowanym w polu RETRY
MINIMUM – jest to czas przez jaki serwery będą przechowywały wszelkie negatywne odpowiedzi
Uwaga: Należy pamiętać, aby wszystkie nazwy domenowe w rekordzie SOA zakończyć kropką.
Uwaga: Wszystkie wartości ttl oraz czasy w poszczególnych polach rekordu SOA domyślnie są podawane w sekundach, aby uprościć zapis dostępne są następujące skróty:
h - godzina d - dzień w - tydzień
Do każdego pliku strefy musi zostać ustawiony jako pierwszy domyślny ttl, następnie dodaje się rekord SOA opisany powyżej. Następnie muszą zostać wymienione serwery DNS dla danej domeny. Kolejna czynność to uzupełnienie pliku strefy o konkretne rekordy zasobów (resource records) dla hostów w naszej domenie.
Ogólna postać rekordu zasobów: nazwa_domenowa [ttl] klasa typ_rekordu dane_rekordu
Pole klasa powinno zawierać dla sieci TCP/IP wartość IN, pole ttl oznacza czas ważności informacji (domyślnie w sekundach), jeśli zostanie pominięty zostanie wykorzystana wartość $ttl z pliku strefy.
Na tym etapie należy wyjaśnić znaczenie poszczególnych najczęściej używanych typów rekordów. Są to:
- A
- – Ten rekord wiąże adres IP z nazwa hosta. Może istnieć tylko jeden rekord dla danego hosta, ponieważ nazwa ta jest uznawana za kanoniczną (oficjalną). Reszta nazw tego hosta musi zostać zdefiniowana jako alias za pomocą rekordu CNAME. Pole dane_rekordu powinno zawierać adres IP w notacji kropkowej.
- CNAME
- – Ten rekord odwzorowuje alias na kanoniczną nazwę hosta. Dzięki temu rekordowi możliwe jest utworzenie wielu nazw tego samego hosta. Pole dane_rekordu powinna zawierać kanoniczna nazwę hosta.
- NS
- – Rekordy te określają wszystkie serwery (master i slave) dla danej domeny. Pole dane_rekordu powinno zawierać kanoniczną nazwę hosta, który jest serwerem strefy.
Przykładowy plik (fragment strefy mojej sieci lokalnej)
$ttl 3h ; domyślny ttl dla strefy ;początek rekordu SOA zoom.pol. IN SOA holly.zoom.pol. out.holly.zoom.pol. ( 2002081001 3H 15M 1W 1D ); koniec rekordu SOA ;Serwery nazw dla domeny zoom.pol zoom.pol. IN NS holly.zoom.pol. ;Rekordy zasobów strefy zoom.pol holly.zoom.pol. IN A 192.168.0.1 antifa.zoom.pol. IN A 192.168.0.3 apacz.zoom.pol. IN A 192.168.0.6 ;Definicje aliasów mail.zoom.pol. IN CNAME holly.zoom.pol. dns.zoom.pol. IN CNAME holly.zoom.pol.
A teraz obiecany plik dla pętli zwrotnej.
localhost. IN SOA localhost. hostmaster.localhost. ( 42 3H 15M 1W 1D ) localhost. IN NS localhost. localhost. IN A 127.0.0.1
Podobnie jak dla strefy odwzorowywanie normalnego pierwszy wpis stanowi domyślny ttl, potem rekord SOA, następnie rekordy zasobów dotyczące serwerów strefy odwzorowywania odwrotnego i na końcu rekordy zasobów dla konkretnej strefy. Jednakże w pliku tym wykorzystuje się do tego celu jeden rekord.
- PTR
- – Rekord ten służy do powiązania nazw w domenie in-addr.arpa z nazwami hostów (jak wspomniano w poprzednich rozdziałach nazwy w tej domenie to odpowiednie oktety adresu IP w notacji kropkowej). Pole dane_rekordu musi zawierać kanoniczną nazwę hosta.
Przykładowy plik (fragment strefy mojej sieci lokalnej)
$ttl 3h ;domyślny ttl dla strefy ;rekord SOA 0.168.192.in-addr.arpa. IN SOA holly.zoom.pol. out.holly.zoom.pol. ( 02030202 3h 1h 1w 1h );koniec rekordu SOA ;Serwer dla strefy 0.168.192.in-addr.arpa 0.168.192.in-addr.arpa. IN NS holly.zoom.pol. ;Rekordy zasobów 1.0.168.192.in-addr.arpa. IN PTR holly.zoom.pol. 3.0.168.192.in-addr.arpa. IN PTR antifa.zoom.pol. 6.0.168.192.in-addr.arpa. IN PTR apacz.zoom.pol.
Odwzorowanie odwrotne pętli zwrotnej
0.0.127.in-addr.arpa. 1D IN SOA localhost. hostmaster.localhost. ( 42 3H 15M 1W 1D ) 0.0.127.in-addr.arpa. IN NS localhost. 1.0.0.127.in-addr.arpa. IN PTR localhost.
Powinieneś umieć juz skonfigurować serwer DNS, pora byś dowiedział się w jaki sposób DNS radzi sobie z trasowaniem poczty elektronicznej.
Kiedy nie było usługi DNS i serwery pocztowe dysponowały tylko plikiem HOST.TXT (lub /etc/hosts) mogły tylko dostarczyć pocztę pod znany adres IP. Jeśli się to nie udawało przeważnie odwlekały wysłanie lub też odsyłały wiadomość do nadawcy. Mechanizm DNS pozwala na definiowanie zapasowych hostów odbierających pocztę, a ponadto umożliwia dodanie nazw domenowych w strefy, które są tylko miejscem przeznaczenia poczty i nie reprezentuje żadnego hosta. Do konfiguracji trasowania poczty wykorzystuje się rekord MX. Przykładowy rekord zasobów dla domeny zoom.pol wygląda następująco.
zoom.pol IN MX 1 holly.zoom.pol.
Należy go przeczytać następująco: host holly.zoom.pol jest wymiennikiem poczty dla domeny zoom.pol. Liczba 1 jest to parametr rekordu MX nazywany wartością preferencji i jest on liczbą całkowita z przedziału 0-65535. Parametr ten odgrywa olbrzymia rolę przy trasowaniu poczty. Zauważ, że nazwa zoom.pol jest tylko miejscem przeznaczenia poczty, nie reprezentuje ona żadnego hosta (przypomnij sobie strefę dla tej domeny). Przykład:
Nasze wymienniki poczty
zoltan.eu.org. IN MX 10 zoltan.eu.org. zoltan.eu.org. IN MX 15 antifa.zoltan.eu.org. zoltan.eu.org. IN MX 20 linux.slupsk.net.
Hostem, do którego ma trafiać docelowo poczta jest zoltan.eu.org ponieważ posiada najmniejszą wartość preferencji, pozostałe dwa hosty są zapasowymi wymiennikami poczty. Oto jak to działa. Kiedy serwer poczty wysyła maila do domeny zoltan.eu.orgi, a host zoltan.eu.org nie działa wysyła pocztę do jednego z wymienników o najmniejszej możliwej wartości preferencji. W tym przypadku do antifa.zoltan.eu.org (gdyby i ten host nie działał poczta trafiłaby do hosta linux.slupsk.net). Aby zapobiec zapętlaniu się tego mechanizmu, tzn. aby przypadkiem host antifa nie słał poczty do hosta linux.slupsk.net lub co jest jeszcze bardziej nonsensowne do samego siebie odrzuca wszystkie rekordy MX o wartości preferencji mniejszej lub równej swojej. W ten sposób host antifa wie, że może przesłać pocztę dalej już tylko do hosta zoltan.eu.org, co uczyni, gdy tylko ten będzie znowu dostępny. Oczywiście serwer poczty na hoście zoltan.eu.org musi być skonfigurowany tak, wiedział, że poczta, którą otrzymuje jest przeznaczona dla niego, a serwery poczty na hostach antifa.zoltan.eu.org oraz linux.slupsk.net muszą być być skonfigurowane jako przekaźniki.
Uwaga: nazwa hosta, który jest wymiennikiem poczty powinna być jego nazwą kanoniczną.
W rozdziale tym zajmiemy się delegowaniem poddomen. O ile jeśli chodzi o strefę odwzorowywania normalnego sprawa jest prosta, to przy delegacji strefy in-addr.arpa pojawia się kilka kłopotów, a jeśli tak, to i kilka sposobów ich rozwiązania.
Jesteśmy posiadaczami domeny linux.pl, powiedzmy, że jakaś organizacja poprosiła nas o to, abyśmy oddelegowali jej domenę firma.linux.pl (oczywiście za darmo nic nie ma :>). Firma ta podała nam adresy IP i/lub nazwy domenowe ich serwerów DNS, do których mamy domenę oddelegować. Oto jakie rekordy należy dodać do strefy linux.pl, aby to zrobić:
firma.linux.pl. IN NS dns.organizacja.pl. firma.linux.pl. IN NS dns2.organizacja.pl.
Jeżeli jednak organizacja chce, aby serwery DNS posiadały nazwy w poddomenie jaka im delegujemy należy dodać następujące rekordy:
firma.linux.pl. IN NS dns.firma.linux.pl. firma.linux.pl. IN NS dns2.firma.linux.pl. dns.firma.linux.pl. IN A 212.160.112.227 ;adresy IP serwerów dns2.firma.linux.pl. IN A 213.25.234.82 ;nazw organizacji
Dwa rekordy A noszą nazwę rekordów spajających (glue records), dlaczego są konieczne ? Otóż odpowiedź jest następująca, serwer szukający nazwy w domenie firma.linux.pl najpierw odpytałby nasz serwer o rekordy NS dla tej strefy. Nasz serwer oczywiście udzieliłby odpowiedzi podając dns.firma.linux.pl oraz dns2.firma.linux.pl, no tak tylko, że nazwy te znajdują się w strefie, o którą zdalny serwer pytał, co oznacza, że nie ma możliwości poznania ich adresów IP – błędne koło. Gdyby nie rekordy klejące tak właśnie by było, dzięki nim nasz serwer DNS zna adresy IP serwerów, do których oddelegowano poddomene i to właśnie je zwraca pytającemu.
Jeżeli oddelegowujemy strefę in-addr.arpa dzieląc ją na granicy oktetu nie ma problemu, postępujemy identycznie jak przy oddelegowywaniu strefy odwzorowywania normalnego. Przykładowo delegujemy z sieci klasy B podsieć klasy C (strefa macierzysta niech dla przykładu będzie 2.15.in-addr.arpa):
1.2.15.in-addr.arpa. IN NS dns.linux.pl. 1.2.15.in-addr.arpa. IN NS dns2.linux.pl.
Problem pojawiłby się gdybyśmy z tej przykładowo stworzonej poddomeny chcieli wydelegować siec 15.2.1.0/25 czyli siec rozciągającą się od adresu 15.2.1.0 do 15.2.1.127. Jest kilka rozwiązań tego problemu lecz my omówimy tutaj to zdefiniowane przez dokumentacje RFC (RFC2317). Polega ono na utworzeniu w pliku strefy 15.2.1 odpowiedniej liczby rekordów CNAME (w tym przypadku 128) wskazujących na nazwy w nowych poddomenach, które są oddelegowywane do odpowiednich serwerów nazw. Oto przykład:
0.1.2.15.in-addr.arpa. IN CNAME 0.0-127.1.2.15.in-addr.arpa. 1.1.2.15.in-addr.arpa. IN CNAME 1.0-127.1.2.15.in-addr.arpa. . . . 127.1.2.15.in-addr.arpa. IN CNAME 127.0-127.1.2.15.in-addr.arpa. ;oddelegowujemy nową domenę 0-127 do odpowiedzialnych za nią serwerów 0-127.1.2.15.in-addr.arpa. IN NS dns.sub.linux.pl. 0-127.1.2.15.in-addr.arpa. IN NS dns2.sub.linux.pl.
Na szczęście nie trzeba samemu wpisywać tych wszystkich aliasów. Ułatwia nam to instrukcja kontrolna $GENERATE. Oto jej zastosowanie dla naszej delegacji:
$GENERATE 0-127 $.1.2.15.in-addr.arpa. IN CNAME $.0-127.1.2.15.in-addr.arpa. 0-127.1.2.15.in-addr.arpa. IN NS dns.sub.linux.pl. 0-127.1.2.15.in-addr.arpa. IN NS dns2.sub.linux.pl.
Trzy instrukcje zamiast stu trzydziestu myślę, że jest to oszczędność pracy. Działanie tej instrukcji jest tak oczywiste, że nie ma sensu go opisywać. Ten, do którego delegujemy tą strefę powinien umieścić odpowiednie instrukcje zone w pliku named.conf swoich serwera DNS.
Jak to działa ? Kiedy wysłane zostaje zapytanie o adres 15.2.1.12 trafia ono do naszego serwera, który rozpoznaje rekord 12.1.2.15.in-addr.arpa jako alias dla nazwy 12.0-127.1.2.15.in-addr.arpa i odsyła pytającego do serwerów nazw strefy 0-127.1.2.15.in-addr.arpa. Serwery nazw tej strefy udzielają pytającemu ostatecznej odpowiedzi w postaci nazwy domenowej przypisanej danemu adresowi (oczywiście jeśli takowa istnieje).
Co jednak gdybyśmy naszej przykładowej klasy B nie chcieli podzielić wzdłuż oktetu ? Jak wtedy wyglądałaby delegacja ? Oto przykład, przyjmijmy, za nasza siec podzielimy wg maski 255.255.252.0 co daje nam 64 sieci po 1024 hosty każda (jedna siec jest wielkości czterech sieci klasy C). Chcemy jedna z tych podsieci wydelegować powiedzmy, że będzie to podsieć rozciągającą się od adresu 15.2.4.0 do adresu 15.2.7.255, aby to uczynić dodajemy następujące rekordy do strefy 2.15.in-addr.arpa:
4.2.15.in-addr.arpa. IN NS dns.linux.pl. 4.2.15.in-addr.arpa. IN NS dns2.linux.pl. . . . 7.2.15.in-addr.arpa. IN NS dns.linux.pl. 7.2.15.in-addr.arpa. IN NS dns2.linux.pl.
Korzystając instrukcji $GENERATE
$GENERATE 4-7 $.2.15.in-addr.arpa. IN NS dns.linux.pl. $GENERATE 4-7 $.2.15.in-addr.arpa. IN NS dns2.linux.pl.
Serwery, do których wydelegowaliśmy tą strefę muszą posiadać po jednej instrukcji zone w pliku named.conf dla każdego rekordu NS (czyli w tym wypadku cztery).
W rozdziale tym zostaną opisane czynności związane z diagnozowaniem oraz testowaniem serwera nazwa za pomocą różnych narzędzi, zostanie omówiony także program rndc ułatwiający i usprawniający prace z demonem named.
Nslookup jest bardzo rozpowszechnionym programem, lecz nie zajmiemy się nim zbyt wiele ponieważ posiada wiele wad i został oficjalnie uznany za przeżytek w dystrybucji BIND 9. Program ten może przyjmować argumenty w wierszu poleceń lub pracować w trybie interaktywnym. Wiersz poleceń używany jest przeważnie gdy mamy zamiar zadać jakiemuś serwerowi pojedyncze zapytanie, tryb interaktywny najlepiej wykorzystywać kiedy będziemy musieli zadawać zapytania do kilku serwerów. Nslookup naraz pracuje z jednym serwerem DNS. Oto przykładowe zapytania w wierszu poleceń.
- nslookup ne.eu.org
- – wysyła zapytanie o adres IP hosta ns.eu.org
- nslookup zoltan.eu.org ns.eu.org
- – wysyła zapytanie o adres IP hosta zoltan.eu.org do serwera nazw ns.eu.org
- nslookup -query=mx linux.net
- – wysyła zapytanie o rekordy mx w strefie linux.net
- nslookup -query=cname slupsk.net
- – wysyła zapytanie o rekordy mx w strefie linux.net
- nslookup -query=mx linux.net
- – wysyła zapytanie o rekordy mx w strefie linux.net
- nslookup 213.25.234.34
- – wysyła zapytanie odwrotne
Tryb interaktywny włącza się wywołując nslookup bez parametrów, komendy wpisujemy po znaku zachęty '>’. Aby zmienić odpytywany serwer używamy dyrektywy: server [nazwa.domenowa.serwera lub jego IP] Aby wybrać typ rekordów używamy wyrażenia set q=typ_rekordu Aby poznać nazwę domenową hosta o danym IP po prostu w wierszu poleceń nslookup wpisujemy to IP, tak samo postępujemy gdy chcemy poznać adres IP hosta którego nazwę domenową znamy. Przykładowa sesja nslookup:
> set q=mx > server dns.tpsa.pl > zoltan.eu.org Server: dns.tpsa.pl Address: 194.204.159.1#53 zoltan.eu.org mail exchanger = 1 zoltan.eu.org. > set q=ns > linux.pl Server: 192.168.0.1 Address: 192.168.0.1#53 linux.pl nameserver = dns4.linux.pl. linux.pl nameserver = dns1.linux.pl. linux.pl nameserver = dns2.linux.pl. linux.pl nameserver = dns3.linux.pl. > server localhost Default server: localhost Address: 127.0.0.1#53 > set q=a > dns.tpsa.pl Server: localhost Address: 127.0.0.1#53 Non-authoritative answer: Name: dns.tpsa.pl Address: 194.204.159.1 >exit
Myślę, że nie wymaga to komentarza.
Program dig (Domain Information Groper) nie jest tak popularny jak opisany wyżej nslookup, nie posiada trybu interaktywnego wszystkie opcje podawane są w wierszu poleceń. Dig inteligentnie interpretuje argumenty tzn. można podać je w dowolnej kolejności – program będzie wiedział, że 'a’, 'mx’ czy tez 'ns’ to typy rekordów a nie nazwy domenowe. Serwer nazw, który chcemy odpytać należy poprzedzić znakiem '@’ może być to nazwa domenowa lub adres IP. Domyślnie odpytywane są serwery nazw z pliku resolv.conf. Ciekawą cechą tego narzędzia jest to że wyniki odpytywania są podane tak jakby przeglądało się plik strefy dla domeny, a dodatkowe komentarze sprawiają, że całość przyjmuje bardzo czytelną formę np oto wynik odpytania o rekordy NS dla domeny wp.pl.
; <<>> DiG 9.2.1 <<>> ns wp.pl ;; global options: printcmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 40401 ;; flags: qr rd ra; QUERY: 1, ANSWER: 3, AUTHORITY: 0, ADDITIONAL: 3 ;; QUESTION SECTION: ;wp.pl. IN NS ;; ANSWER SECTION: wp.pl. 86400 IN NS ns1.wp.pl. wp.pl. 86400 IN NS ns2.wp.pl. wp.pl. 86400 IN NS dns.task.gda.pl. ;; ADDITIONAL SECTION: dns.task.gda.pl. 86400 IN A 153.19.250.100 ns1.wp.pl. 86400 IN A 212.77.102.200 ns2.wp.pl. 86400 IN A 153.19.102.182 ;; Query time: 387 msec ;; SERVER: 127.0.0.1#53(127.0.0.1) ;; WHEN: Fri Aug 23 03:02:20 2002 ;; MSG SIZE rcvd: 134
Pierwszy wiersz to wersja programu oraz powtórzenie zapytania. Skróty następujące po słowie flags oznaczają:
- qr
- - wskazuje, że komunikat jest odpowiedzią
- aa
- - wskazuje, że odpowiedź jest autorytatywna (w tym przypadku nie jest bo udzielił jej serwer, który nie jest autorytatywny dla domeny wp.pl)
- rd
- - wskazuje, że w zapytaniu ustawiony był bit rekurencji
- ra
- - wskazuje, że odpytany serwer obsługuje rekurencyjne zapytania, gdyby nie obsługiwał flaga ta nie zostałaby ustawiona, a serwer potraktowałby zapytanie jako iteracyjne
Pozostałe dane w tym wierszu to liczba zapytań wysłanych, ilość otrzymanych w odpowiedzi rekordów w sekcji odpowiedzi (ANSWER), zwierzchności (AUTHORITY) oraz dodatkowej (ADDITIONAL). Jak widać w odpowiedzi otrzymaliśmy trzy serwery nazw odpowiedzialne za domenę wp.pl, a w sekcji dodatkowej także ich rekordy A im odpowiadające. Ostatnie cztery linie informują o tym ile czasu trwało zapytanie, jaki serwer został odpytany i kiedy, oraz rozmiar (w bajtach) zapytania i odpowiedzi.
Na koniec kilka przykładowych zapytań:
- dig @zoltan.eu.org zoltan.eu.org axfr
- - przeprowadza transfer strefy zoltan.eu.org od serwera zoltan.eu.org
- dig ns wp.pl
- - odpytuje jeden z serwerów w pliku resolv.conf o rekordy NS domeny wp.pl
- dig -x 213.25.234.82 @dns.tpsa.pl
- - wykonuje zapytanie odwrotne do serwer dns.tpsa.pl
Program host posiada podobne możliwości jak wspomniani wyżej jego poprzednicy. Jest to dość proste w użyciu narzędzie, dlatego też nie bede się zbytnio na jego temat rozpisywał. Na szczególną uwagę zasługuje w nim opcja umożliwiająca sprawdzenie poprawności delegacji strefy. Oto przykład:
$ host -t ns zoltan.eu.org ns.eu.org Using domain server: Name: ns.eu.org Address: 137.194.2.218#53 Aliases: zoltan.eu.org name server ATECOM.SKI.SLUPSK.PL. zoltan.eu.org name server PB82.SLUPSK.SDI.TPNET.PL. $ host -t ns zoltan.eu.org atecom.ski.slupsk.pl Using domain server: Name: ATECOM.SKI.SLUPSK.PL. Address: 212.160.112.222#53 Aliases: zoltan.eu.org name server pb82.slupsk.sdi.tpnet.pl. zoltan.eu.org name server atecom.ski.slupsk.pl. $ host -C zoltan.eu.org. Nameserver atecom.ski.slupsk.pl: zoltan.eu.org SOA pb82.slupsk.sdi.tpnet.pl. out.holly.linux.slupsk.net. 2002081801 10800 900 604800 86400 Nameserver pb82.slupsk.sdi.tpnet.pl: zoltan.eu.org SOA pb82.slupsk.sdi.tpnet.pl. out.holly.linux.slupsk.net. 2002081801 10800 900 604800 86400
Najpierw od autorytatywnego serwera nazw strefy zwierzchniej pobralismy rekordy NS dla interesującej nas strefy. Proszę zauważyć, że program host pokazał jakiego serwera użył do wykonania zapytania. Następnie od dowolnego z serwerów tej strefy pobieramy rekordy NS, którą on przechowuje. Jeżeli rekordy są takie same to połowa sukcesu, oznacza to, że dane w strefie nadrzędnej i podrzędnej są spójne. Jeśli liczba rekordów uzyskana od jednego serwera jest różna od tych uzyskanych od drugiego lub gdy rekordy są różne to właśnie zobaczyliśmy powód np. takiego komunikatu w logach:
named[11312]: lame server resolving 'pepe.nsb.pl' (in 'nsb.pl'?): 158.75.61.4#53
Kolejnym krokiem jest wywolanie programu host z parametrem 'C' sprawdzi on każdy serwer wymieniony przy rekordzie NS pod kątem zwierzchności nad badaną strefą, jeżeli serwer jest autorytatywny to zwróci odpowiedni rekord SOA. Liczba zwróconych rekordów SOA musi być taka sama jak liczba rekordów NS danej strefy.
Po wiecej informacji na temat programu host odsyłam do pomocy lub podręcznika systemowego.
Aby umożliwić korzystanie z narzędzia rndc konieczne jest dodanie do pliku named.conf następujących linii.
controls { inet * allow {any;} keys { "rndc-key"; }; }; key "rndc-key" { algorithm hmac-md5; secret "xV20v+w5rYs=" };
Objaśnienie opcji:
- inet
- - serwer nasłuchuje na polecenia kontrolne domyślnie na porcie 953
- secret
- - przechowuje zakodowane hasło. Aby wygenerować to hasło należy użyć polecenia dnssec-keygen np: dnssec-keygen -a hmac-md5 -b 64 -n host jakies_haslo wynikiem tego polecenia będą dwa pliki, w każdym z nich będzie znajdowało się zakodowanie hasło. Po więcej informacji o tym programie odsyłam do podręcznika systemowego.
- allow
- - jest to lista hostów, od których serwer może przyjmować komunikaty kontrolne
- algorithm
- - algorytm kodowania hasła, hmac-md5 jest jedyny obecnie obsługiwanym algorytmem
- keys
- - lista kluczy rozpoznawana przez serwer nazw, każdy z kluczy wymieniony na tej liście musi zostać zdefiniowany jak przykładowy klucz rndc-key za pomocą dyrektywy key.
oraz stworzenie pliku /etc/rndc.conf o zawartości:
options { default-server localhost; default-key "rndc-key"; }; key "rndc-key" { algorithm hmac-md5; secret "xV20v+w5rYs="; };
Wyjaśnienie opcji:
- default-server
- - do jakiego serwera domyślnie wysłać komunikaty kontrolne w przypadku nie zdefiniowania serwera w wierszu poleceń
- default-key
- - jakiej nazwy klucza użyć domyślnie jeżeli nie została zdefiniowana w wierszu poleceń
- algorithm
- - patrz opis dla pliku named.conf
- secret
- - przechowuje zakodowane hasło wpis musi być identyczny jak ten w pliku named.conf serwera, do którego wysyłamy komunikaty kontrolne
Jeżeli zarządzamy większą ilością serwerów możemy w pliku rndc.conf użyć takiej instrukcji dla każdego serwera.
server zoltan.eu.org { key "zoltan-key"; };
Oczywiście musimy zdefiniować ten klucz w pliku rndc.conf hosta z którego będziemy wysyłać komunikaty, a także w pliku named.conf serwera do którego te komunikaty będziemy wysyłać (i dodać go do listy kluczy obsługiwanych przez serwer).
Uwaga: Należy zadbać, aby pliki named.conf oraz rndc.conf były dostępne tylko i wyłącznie dla obsługi serwera nazw.
Ważniejsze funkcje programu rndc:
- reload
- - przeładowuje pliki stref oraz plik named.conf
- reconfig
- - przeładowuje plik named.conf oraz tylko nowe strefy
- dumpdb
- - zrzuca do katalogu domowego serwera zawartość cache
- flush
- - czyści cache (pamięć podręczną)
Przykładowe wywołania:
- rndc reload
- - wykona reload dla domyślnego serwera używając domyślnego klucza
- rndc -s zoltan.eu.org reload
- - wykona reload serwera zoltan.eu.org używając klucza z dyrektywy server jeżeli taka istnieje dla tego serwera, jeżeli nie użyje klucza domyślnego
- rndc -s ns.eu.org -y eu-key reload
- - wykona reload serwera ns.eu.org używając klucza o nazwie eu-key
BIND posiada bardzo rozbudowany mechanizm rejestracji zdarzeń, który można skonfigurować na wiele sposobów dostosowując go tym samym nawet do najbardziej wymyślnych potrzeb administratora. Jednak odpowiednia konfiguracja logowania wymaga od administratora przede wszystkim eksperymentów. Ja ograniczę się w tym artykule do podania pewnych przykładów, które sam sprawdziłem i informacje jakie rejestrowałem uznałem za istotne dla mnie, oczywiście potrzeby są rozne w zależności od osoby, dlatego rozdzial ten proszę traktować jako mala prezentacje możliwości jakie oferuje pakiet BIND w tej dziedzinie.
Istnieje wiele kategorii komunikatów, oto niektóre z nich (* oznacza, ze kategoria ta istnieje tylko w BIND 9, ** w BIND 8):
- default
- - jeśli nie określisz kanałów dla innych kategorii to serwer wysyła wszystkie komunikaty ich dotyczące do kanału przypisanego kategorii default, (BIND 8 I 9). Dla BIND 8 trafiają tu jeszcze wszystkie inne komunikaty, które nie zostały sklasyfikowane (tzn. nie posiadają własnej kategorii)
- general*
- - Jest to specjalnie wydzielona kategoria obejmująca wszystkie niesklasyfikowane komunikaty serwera (tzn. te, które nie maja własnej kategorii)
- eventlib**
- - informacje o zdarzeniach systemowych
- panic**
- - informacje o problemach powodujących zamkniecie serwera
- packet**
- - informacje o dekodowaniu odebranych i wysłanych pakietów
- lame-servers
- - informacje o błędnych delegacjach
- update
- - informacje o dynamicznych uaktualnieniach
- statistics**
- - raport o działaniu serwera
- security
- - informacje dotyczące zezwoleń lub ich braku na dane operacje
- queries
- - informacje o otrzymywanych przez serwer zapytaniach
- xfer-in
- - informacje o transferach stref do lokalnego serwera
- xfer-out
- - informacje o transferach stref z lokalnego serwera
Pozostałe nie opisane kategorie to: cname**, client*, config, database*, db**, dnssec*, insist**, load**, maintenance**, ncache**, network*, notify, os**, parser**, resolver*, response-checks**.
Każdy komunikat posiada typ ważności, jest ich (typów) w sumie siedem oto one od najważniejszego poczynając, a na najmniej ważnym kończąc: critical, error, warning, notice, info, debug [level], dynamic.
Jeżeli pominiemy parametr level przy typie debug, zostanie domyślnie użyta wartość 1. Aby włączyć tryb diagnostyczny należy użyć narzedzia rndc (rndc trace). Typ ważności debug ustala na sztywno szczegółowość komunikatów diagnostycznych tzn. jeżeli ustawiliśmy go np. na 2 to niezależnie ile razy wyślemy do serwera polecenie śledzenia szczegółowość zawsze pozostanie 2. Inaczej jest jeśli wybierzemy typ dynamic wtedy szczegółowość będzie zależała od tego ile wyślemy poleceń śledzenia. Tryb diagnostyczny wyłącza się poleceniem rndc notrace.
Każda kategoria musi trafić do jakiegoś kanału. Kanał określa gdzie konkretnie maja trafić komunikaty danej kategorii i ważności. Może to być plik, demon syslog, czy tez kanał null (mam nadzieję, że nie muszę wyjaśniać losu informacji trafiających do tego kanału). BIND domyślnie definiuje cztery rodzaje kanałów, których nie można usunąć lub zmienić, a są to: default_syslog, default_debug, default_stderr, null. Pierwszy z nich wysyła informacje do demona syslog drugi zapisuje je w pliku named.run, trzeci wysyła na standardowe wyjście błędów named'a, czwarty nie wymaga komentarza.
Tak samo jak kanały, domyślnie zdefiniowane są kategorie wiadomości, które maja do nich trafić i tak w BIND 9:
category default { default_syslog; default_debug; };
BIND 8
category default { default_syslog; default debug; }; category panic { default_syslog; default_stderr; }; category packet { default_debug; }; category eventlib { default_debug; };
Wiemy juz jak definiować inne kategorie i ustalać dla nich kanały na podstawie przytoczonych domyślnych ustawień BIND'a, pora, aby nauczyć się definiować właśnie kanały. Ważna uwaga możemy przedefiniować, to do jakich kanałów trafiają domyślne kategorie, zostanie to pokazane w przykładzie niżej.
channel zapytania { file "query.log" versions 3 size 20k; severity dynamic; print-time yes; print-severity yes; print-category yes; }; channel zap_syslog { syslog deamon; severity info; };
Zdefiniowaliśmy dwa nowe kanały pierwszy z nich to plik o nazwie query.log, który maksymalnie może osiągnąć rozmiar 20 kB (po osiągnięciu tego rozmiaru BIND zaprzestanie logowania), ustaliliśmy, że maksymalnie mogą istnieć trzy dodatkowe kopie tego pliku powstające przy restartowaniu serwera, dodatkowo określiliśmy, że do każdego zalogowanego komunikatu ma zostać dodany tzw. timestamp oraz informacja jakiej kategorii jest to komunikat oraz poziom jego ważności, oczywiście nie zobaczymy nic w pliku query.log dopóki nie włączymy trybu diagnostycznego, co zostało opisane wyżej przy omawianiu tegoż trybu. Drugi kanał będzie wysyłał wszystkie komunikaty do demona syslog (poziom ważności w tym wypadku może być maksymalnie info z tego prostego powodu, że nie można wysyłać komunikatów diagnostycznych serwera DNS do demona syslog).
Wszystkie zdefiniowane kanały oraz to, do jakich kanałów maja trafiać informacje z danych kategorii umieszczamy wewnątrz pliku named.conf w dyrektywie logging.
logging { channel zapytania { file "query.log" versions 3 size 20k; severity dynamic; print-time yes; print-severity yes; print-category yes; }; channel zap_syslog { syslog deamon; severity info; }; channel transfer { file "xfer.log" versions 2 size 10k; severity info; print-time yes; print-category yes; }; category default { default_syslog; }; category queries { zapytania; zap_syslog; }; category xfer-in { transfer; }; category xfer-out { transfer; }; category lame-servers { null; }; };
Oto co wynika z powyższej konfiguracji. Ponieważ denerwowały mnie wszystkie informacje na temat błędnych delegacji w innych strefach postanowiłem je wyrzucić. Interesowało mnie kto stara się pobrać moje strefy, wiec postanowiłem logować wszystkie transfery stref do osobnego pliku, chciałem znać szczegóły dotyczące zapytań jakie obsługuje mój serwer wiec loguje je do pliku query.log (oczywiście jeśli włączę debugowanie), informacje na poziomie info dotyczące zapytań wysyłane są do demona syslog (mogłem oczywiście użyć kanału default_syslog, ale chciałem pokazać jak zbudować kanał wysyłający informacje do tegoż demona). Nie chcąc, aby wszystkie pozostałe komunikaty BIND zapisywał w pliku named.run przedefiniowałem kategorię default, aby wysyłała je tylko do syslog.
RFC2308 definiuje nowe użycie tego pola, a mianowicie, jako domyślnego ttl-a dla buforowania odpowiedzi negatywnych, dotychczas pole to było używane do ustawiania domyślnego czasu ttl dla rekordów, które nie miały go zdefiniowanego. Nowe RFC zaleca definiowanie tego czasu używając następującego wyrażenia na początku pliku strefy.
$TTL wartość_liczbowa
Dla ciekawostki dodam, że pole to było przedefiniowywane już kilkakrotnie, a pierwotnie jego wartość oznaczała minimalny czas przez jaki mają być buforowane rekordy zasobów danej strefy.
Zagadnienie bezpieczeństwa DNS jest bardzo szerokie, rozpoczynając od odpowiedniej konfiguracji samego serwera nazw, poprzez TSIG (zabezpieczenia kluczem transakcji tj. transferów stref itp.), DNSSEC (DNS Security Extensions - wykorzystanie kryptografii z kluczem publicznym do podpisywania danych w strefach), a kończąc na zaawansowanych konfiguracjach sieci z hostami bastionowymi, wewnętrznymi serwerami nazw.
Istnieje wiele opcji konfiguracyjnych serwera DNS, które znacznie ograniczają dostęp osobom niepowołanym do danych jakie on przechowuje. Wszystkie poniższe dyrektywy dodawane są do pliku named.conf. Oto one:
- version "string";
- - umieszczana wewnątrz dyrektywy options, ustawia odpowiedź na zapytanie version.bind utrudniając identyfikację naszego serwera nazw złośliwej osobie, która np właśnie przeszukuje www.securityfocus.com w poszukiwaniu odpowiedniego exploita
- allow-query { lista_adresów; };
- - opcja, dzięki której zyskujemy kontrolę nad tym kto może odpytywać nasz serwer nazw, lista_adresów to adresy hostów lub sieci, którym na to pozwalamy np: { 192.168.0/24; 127.0.0.1; }. Opcje te możemy umieścić wewnątrz dyrektywy options jest wtedy traktowana jako globalna, lub wewnątrz dyrektywy zone strefy, dla której chcemy wprowadzić ograniczenia.
- allow-transfer { lista_adresów; };
- - opcja ta ogranicza liczbę hostów, które mogą przeprowadzić transfer strefy, podobnie jak w poprzednim przypadku lista_adresów to adresy hostów, którym na ewentualne transfery zezwolimy, dla serwerów, które są podstawowymi powinna zawierać adresy serwerów podrzędnych, serwery podrzędne nie powinny zezwalać nikomu na transfer strefy, opcja ta może być użyta wewnątrz dyrektywy options lub wewnątrz dyrektywy zone dla danej strefy
- recursion no;
- - opcja ta całkowicie uniemożliwia przetwarzanie zapytań rekurencyjnych naszemu serwerowi nazw
- allow-recursion { lista_adresów; };
- - opcja ta informuje nasz serwer, aby przetwarzał zapytania rekurencyjne tylko i wyłącznie od hostów, które są na liście adresów
Tworzenie plików stref może wydawać się czynnością dość męcząca szczególnie jeżeli nasza strefa odwzorowania normalnego czy tez odwrotnego posiada wiele rekordów zasobów. Na szczęście istnieje kilka skrótów, które bardzo usprawniają i przede wszystkim przyspieszają tworzenie pliku strefy.
Pierwszy parametr instrukcji zone czyli nazwa domenowa strefy jest określana mianem źródła (origin) i jest ona automatycznie dodawana do każdej nazwy domenowej nie zakończonej kropką w pliku strefy. Do zmiany źródła wewnątrz pliku strefy stosuje się instrukcje $ORIGIN nowe_zrodlo.
Jeżeli nazwa domenowa jest taka sama jak źródło można ją zapisać używając znaku '@' (at). Taki zapis wykorzystywany jest przeważnie w rekordach SOA.
Jeżeli w polu nazwa_domenowa rekordu zasobów znajduje się znak spacji lub tabulacji to serwer użyje nazwy z ostatniego rekordu zasobu, który posiadał nazwę inną niż spacja lub znak tabulacji. Ten zapis wykorzystywany jest gdy konfigurujemy wiele typów rekordów dla jednego hosta.
Oto jak wyglądają przykładowe pliki stref po zastosowaniu skrótów:
strefa odwzorowania normalnego, źródło - zoom.pol.
$ttl 3h ;do wszystkich nazw nie zakończonych kropką zostaje dodane źródło ;źródło jest takie samo jak nazwa domenowa wiec stosuje się znak '@' @ IN SOA holly out.holly ( 2002081001 3H 15M 1W 1D ) IN NS holly ;nazwą jest spacja lub tabulatorem poprzedni rekord ;zawierający nazwę inną niż spacja czy tabulator to SOA ;wiec domyślnie wiadomo, że rekord ten dotyczy nazwy źródłowej ;Rekordy zasobów strefy zoom.pol holly IN A 192.168.0.1 IN MX 1 holly ;nazwą jest spacja lub tabulatorem wiec ;rekord dotyczy hosta holly antifa IN A 192.168.0.3 apacz IN A 192.168.0.6 ;Definicje aliasów mail IN CNAME holly dns IN CNAME holly
strefa odwzorowania odwrotnego, źródło - 0.168.192.in-addr.arpa.
$ttl 3h @ IN SOA holly.zoom.pol. out.holly.zoom.pol. ( 02030202 3h 1h 1w 1h ) IN NS holly.zoom.pol. 1 IN PTR holly.zoom.pol. 3 IN PTR antifa.zoom.pol. ;jak wspomniano wyżej źródło można zmienić w ;dowolnym miejscu pliku strefy $ORIGIN zoom.pol. 6.0.168.192.in-addr.arpa. IN PTR apacz
Mechanizm rotowania rekordów jest szczególnie przydatny, gdy posiadamy kilka hostów pełniących te same funkcje (np. mirrorowane serwery ftp) i chcemy w miarę równomiernie rozłożyć ruch pomiędzy nimi. Dokonuje się tego umieszczając w pliku strefy następujące rekordy:
ftp.linux.pl. 60 IN A 213.25.234.82 ;serwer ftp ftp.linux.pl. 60 IN A 212.160.112.227 ;przykładowy mirror pierwszy ftp.linux.pl. 60 IN A 213.25.234.170 ;przykładowy mirror drugi
Jak to działa ?
Bardzo prosto, w momencie kiedy serwer otrzymuje zapytanie o nazwę ftp.linux.pl zwraca adresy w kolejności:
213.25.234.82, 212.160.112.227, 213.25.234.170
otrzymując kolejne zmienia ich kolejność w następujący sposób:
212.160.112.227, 213.25.234.170, 213.25.234.82
na trzecie zapytanie odpowie:
213.25.234.170, 213.25.234.82, 212.160.112.227
a na czwarte:
213.25.234.82, 212.160.112.227, 213.25.234.170
I tak w kółko. Mechanizm ten jest domyślnie włączony, jednak, aby zapewnić mu prawidłowe funkcjonowanie, należy dla rotowanych rekordów ustawić Mały ttl, przykładowo na 60 sekund jak uczyniono to powyżej.
Gdy jednak posiadamy główny serwer ftp oraz np. jeden zapasowy i chcielibyśmy, aby zapasowy używany był tylko wtedy, gdy główny nie działa, rotowanie rekordów tylko przeszkadza Aby je zmienić należy posłużyć się podinstrukcją dyrektywy options - rrset-order. Jej postać:
rrset-order { class IN type ANY name "*.zoltan.eu.org" order fixed; //specyfikacja kolejności };
Słowo order oznacza w jakiej kolejności będą zwracane rekordy, dostępne są następujące słowa kluczowe:
- fixed
- - rekordy będą zawsze zwracane w tej samej kolejności
- cyclic
- - rekordy będą rotowane
- random
- - rekordy będą zwracane losowo
Parametr name określa domenę jakiej dotyczy ta reguła (domyślnie wszystkie czyli "*"). Parametry class oraz type jak nie trudno się domyślić oznaczają odpowiednio klasę rekordów oraz ich typ (domyślnie jest to klasa IN oraz wszystkie typy rekordów). Parametry domyślne jeśli nam odpowiadają możemy pominąć, wiec specyfikacja kolejności dla wszystkich rekordów byłaby taka: order fixed;). Dozwolona jest tylko jedna instrukcja rrset-order, ale może ona zawierać wiele specyfikacji kolejności. Wykorzystywana jest pierwsza pasująca do danej grupy rekordów.
Chciałbym zaznaczyć, że rozwiązanie tego problemu wykorzystujące instrukcje rrset-order jest zakłócane przez buforowanie nazw przez serwery, jednak lepszy rydz niż nic. (Istnieje nowy typ rekordu SRV, który jest doskonałym rozwiązaniem tego problemu, lecz nie jest on zbytnio rozpowszechniony, a na dodatek delikatnie mówiąc istnieje bardzo mało aplikacji klienckich obsługujących ten typ rekordu.
TPSA nie wykorzystuje sposobu delegacji strefy odwrotnej opisanego przeze mnie, a niestety zyskalibyśmy wtedy czytelność i porządek danych. Nie będę na łamach tego artykułu tłumaczył jak zarejestrować własną strefę w TPSA, odsyłam do strony http://www.tpnet.pl/rev.php gdzie proces postępowania rejestracyjnego został dokładnie wytłumaczony krok po kroku.
W opisie tym całkowicie pominąłem zagadnienie IPv6 w DNS, ponieważ jest to obszerny temat, a artykuł i tak rozrósł się do dość dużych rozmiarów. Przypuszczam, że temu tematowi poświęcę osobny artykuł (który w najbliższym czasie powinien zostać opublikowany na stronie).
W paragrafie bezpieczeństwo nie omówiłem mechanizmów TSIG oraz DNSSEC. Jeżeli chodzi o ten pierwszy, sądzę, że powinienem w niedługim czasie uzupełnić artykul. Opis DNSSEC nie pojawi się wogóle. Powodem jest, brak czasu, obszerność tematu, a co najważniejsze prace nad mechanizmem DNSSEC ciągle trwają i pewne aspekty jego działania mogą się jeszcze zmienić, obecna specyfikacja znajduje się w RFC2535.
...prosze kierować na adres out@holly.linux.slupsk.net
Szczególnie proszę wytykać mi te fragmenty, które wydają się być niezrozumiale.
Archiwalny news dodany przez użytkownika: _out_.
Kliknij tutaj by zobaczyć archiwalne komentarze.